
好面的糖炒栗子
好面的糖炒栗子!坚持打基础、提素质!好好笔试面试!

💻浏览器
✅从在地址栏输入url地址到页面渲染的详细过程
MDN原文 原文嵌套原文,建议大家好好看一下。我爱MDN
这一段过程主要分为五个阶段,分别是:导航、响应、解析、渲染、交互
导航
首先在浏览器中输入URL
查找缓存
浏览器先查看浏览器缓存-系统缓存-路由缓存中是否有该地址页面,如果有则显示页面内容。如果没有则进行下一步。
- 浏览器缓存:浏览器会记录DNS一段时间,因此,只是第一个地方解析DNS请求;
- 操作系统缓存:如果在浏览器缓存中不包含这个记录,则会使系统调用操作系统, 获取操作系统的记录(保存最近的DNS查询缓存);
- 路由器缓存:如果上述两个步骤均不能成功获取DNS记录,继续搜索路由器缓存;
- ISP缓存:若上述均失败,继续向ISP搜索(ISP本身是一种宽带接入提供商给网页批量访问加速的技术。 ISP会将当前访问量较大的网页内容放到ISP服务器的缓存中,当有新的用户请求相同内容时,可以直接从缓存中发送相关信息,不必每次都去访问真正的网站,从而加快了不同用户对相同内容的访问速度,同时也能节省网间流量结算成本)。
DNS域名解析
浏览器向DNS服务器发起请求,解析该URL中的域名对应的IP地址。这个IP地址会在浏览器缓存中记录一段时间↑
DNS服务器是基于UDP的,因此会用到UDP协议。
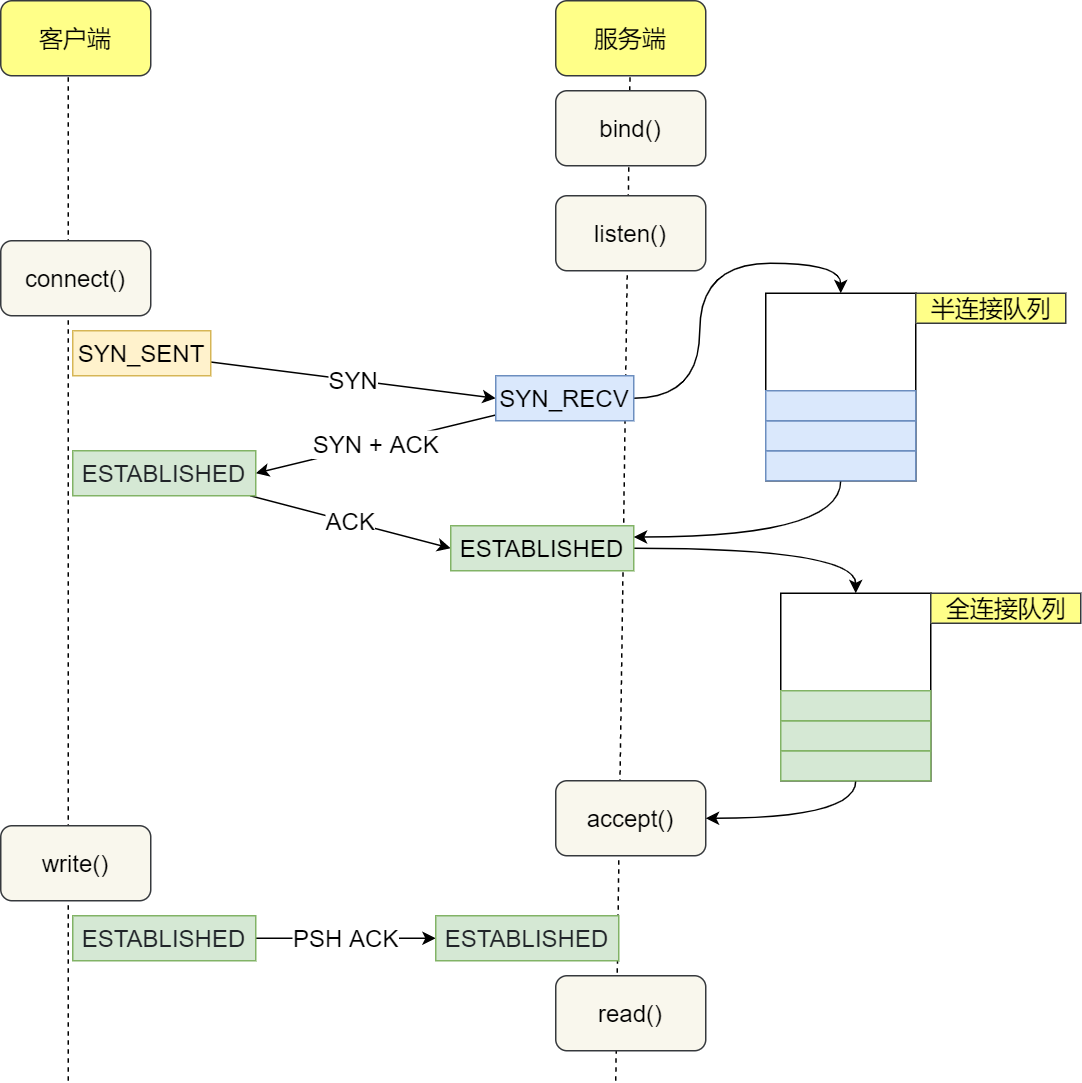
建立TCP连接
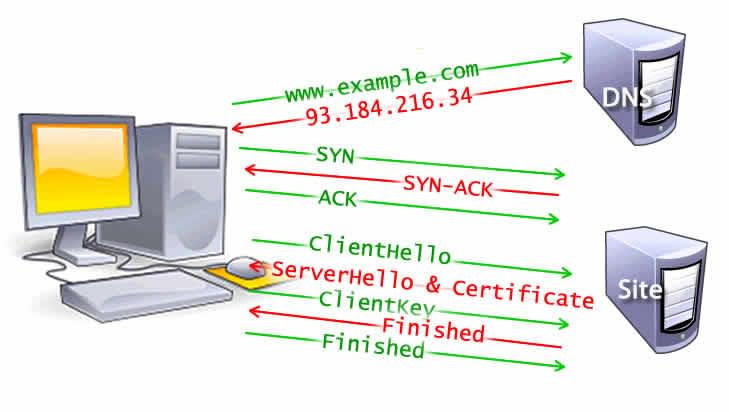
解析出IP地址后,根据IP地址和默认80端口,和服务器建立TCP连接
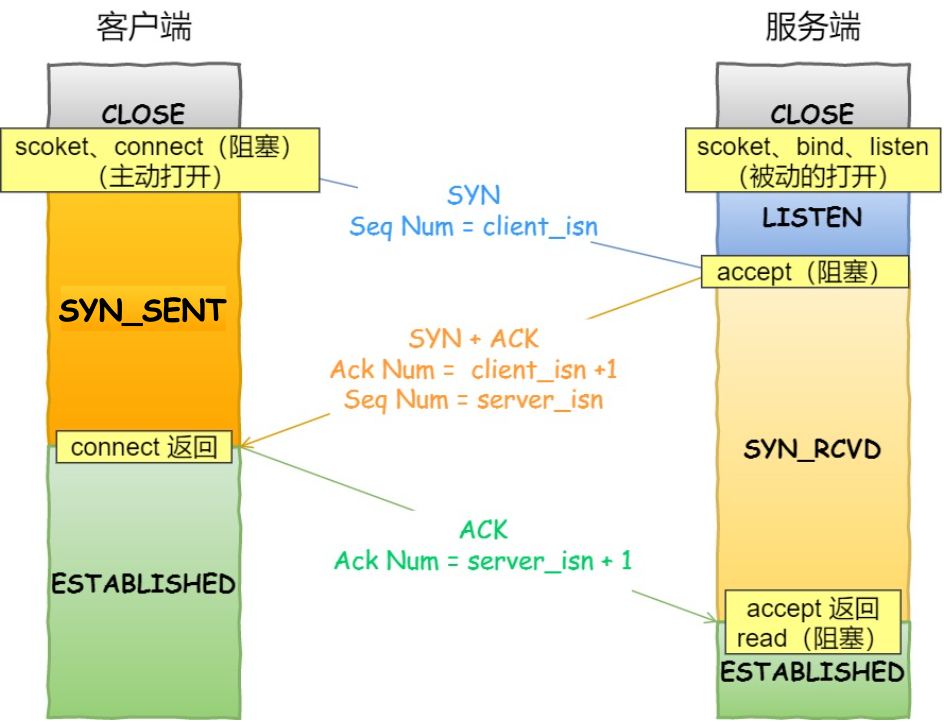
三次握手(TCP Handshake)
三次握手SYN-SYNACK-ACK,与服务器建立连接。
三次握手过程
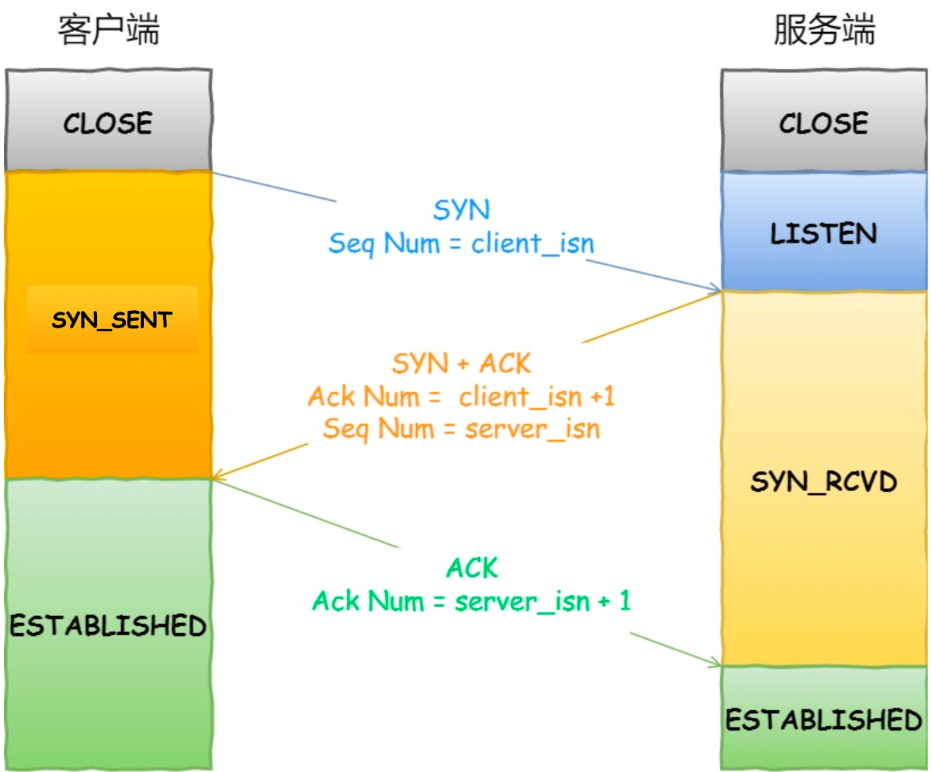
图解释得已经非常清除了
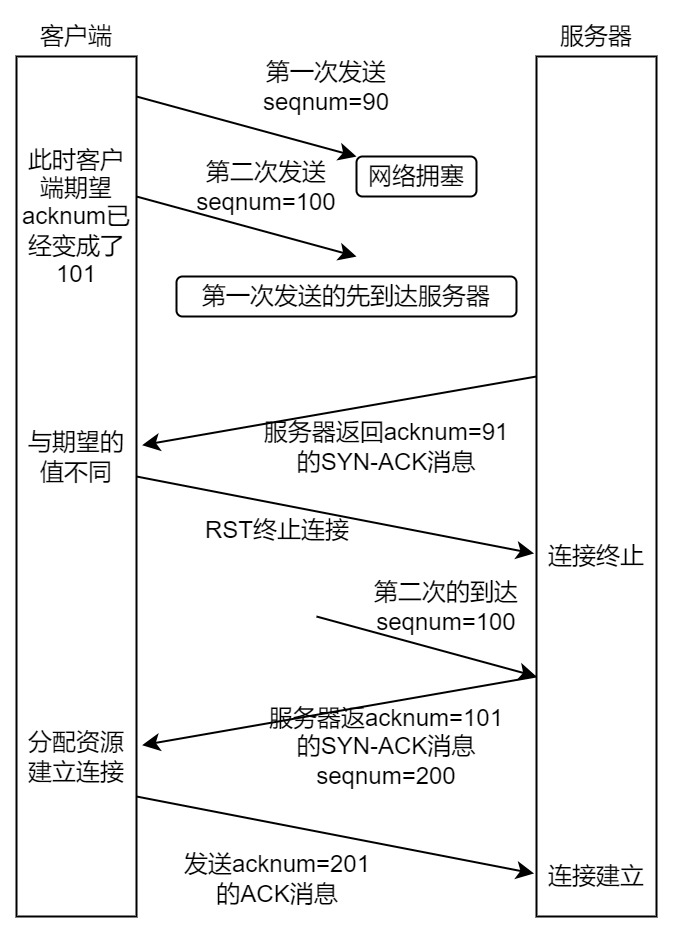
为什么是三次?
阻止重复历史连接的初始化:浅浅做了个图↓(假设两次握手)
- 客户端发送SYN报文,第一次拥塞第二次发出第一次先到
- 服务器接收到第一个,回复ACK-SYN报文,之后直接发送数据
- 结果不是,终端,数据作废
同步双方初始序列号:
seqnum = client isn acknum = seqnum + 1 seqnum = server isn acknum = seqnum + 1避免浪费资源:
- 可合并→
seqnum = client isn (acknum = seqnum + 1 seqnum = server isn) acknum = seqnum + 1 - 避免历史链接重复建立而产生的冗余连接
- 可合并→
以上三点才能建立一个比较可靠的链接。
为什么每次建立TCP连接的初始序列号是不一样的?
一是如果出现,那上面这种情况就莫得行了。
ISN是如何随机生成的?
已经有了IP的MTU分片,为什么还要进行TCP的MSS分片?
第一次握手消失会发生什么?
客户端处在SYN_SENT状态,等待服务端返回ACK报文,但是第一次握手消失,服务端一直处在CLOSE/LISTEN状态,客户端也因为一直收不到服务端回复而进行超时发送,直到达到最大发送次数tcp_syn_retries,停止发送,返回CLOSE状态。
第二次握手消失会发生什么?
第二次握手消失,此时不仅客户端没有收到ACK报文,服务器发送了SYN-ACK报文也一直处在半连接SYN_RCVD状态等待客户端发ACK。客户端以为服务端没收到自己发出的SYN报文,于是超时重传;服务端也认为客户端没收到SYN-ACK报文,于是超时重传。直到达到了最大发送次数tcp_syn_retries&tcp_synack_retries而停止发送,都返回CLOSE状态。
第三次握手消失会发生什么?
第三次握手消失,客户端已然是连接状态ESTABLISHED,服务端则依然是是在等待ACK报文的半连接状态。这个时候服务器会认为客户端可能没有收到自己发的SYN-ACK,于是超时重传,直到达到最大发送次数,返回关闭状态。
SYN攻击是啥,如何避免?
SYN攻击核心攻击方式就是攻击者仿了巨量不同的IP地址给指定服务器发送SYN报文,服务端每次收到一条SYN报文都会进入半连接状态,并给IP地址发送SYN-ACK报文。但是不妙的是,服务器是没有收到这些IP地址应答的,这导致服务器半连接队列(也就是SYN队列)逐渐占满,使得正常来服务器握手的客户端获得不到服务器的服务空间。
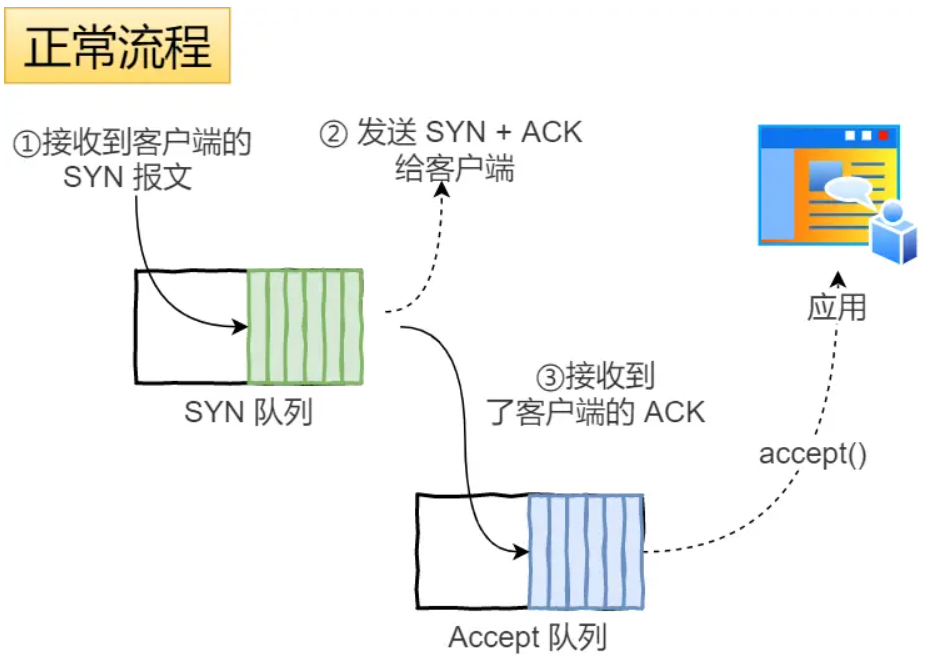
避免
- 调大
netdev_max_backlog - 增大TCP半连接队列
- 开启
tcp_syncookies - 减少SYN+ACK重传次数
TLS协商(TLS/SSL Handshake SSL被TLS取代了)
- 时间:TLS传输层安全协议,该段握手在三次握手建立连接之后发生。
- 内容:
- 指定要使用的TLS版本
- 决定密码套件
- 通过服务器公钥和SSL证书颁发机构的数字签名来验证服务器的身份
- 生成对话密钥,以在握手完成后使用对称加密。
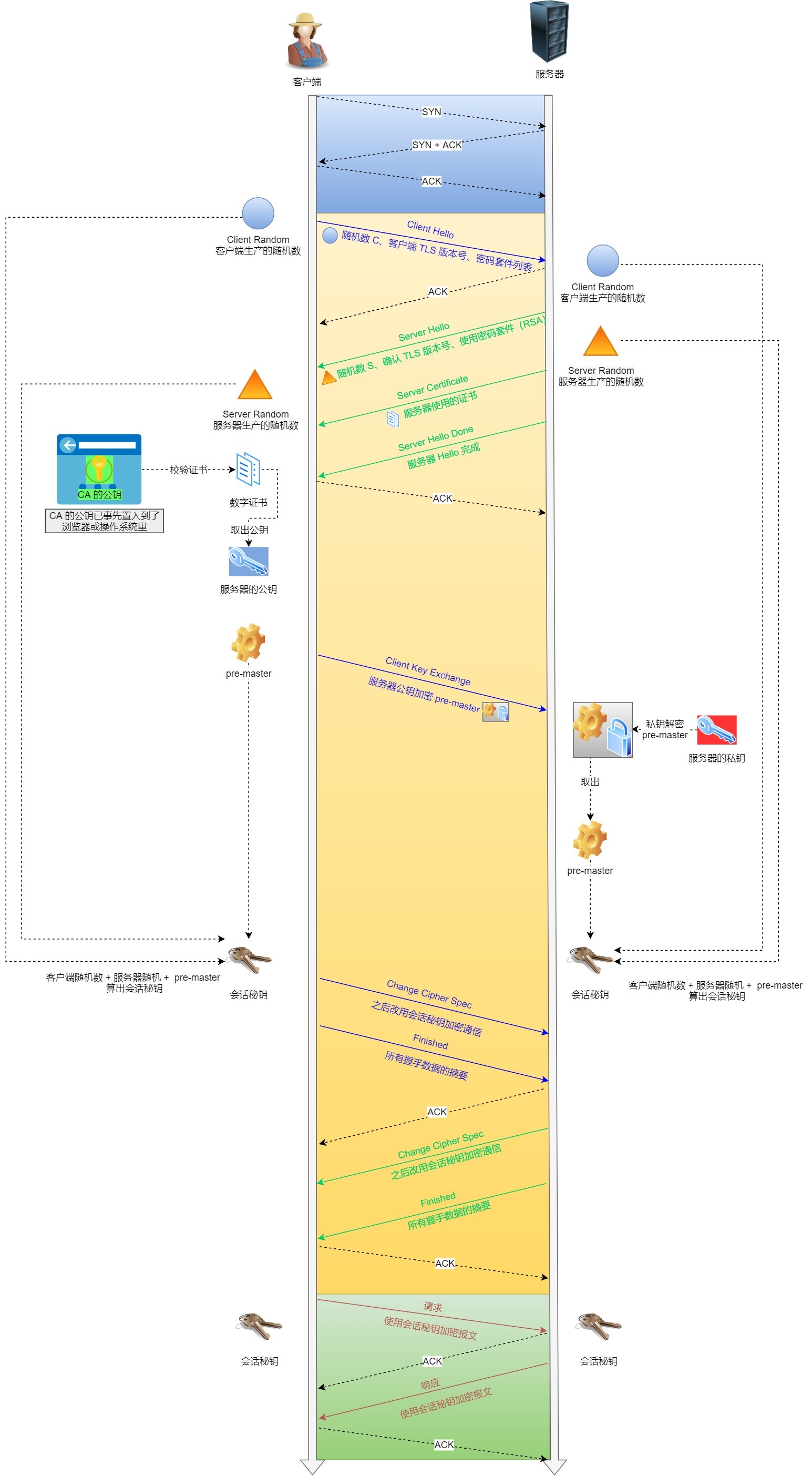
- 步骤(以RSA 密钥为例):
- client hello:客户端发送问候消息,发送包含客户端支持的TLS版本、支持的密码套件、客户端随机数client random的消息。
- server hello:服务器回复问候消息,发送包含SSL证书、服务器选择的密码套件、server random的消息。
- 身份验证:客户端使用证书颁发机构验证服务器的SSL证书,以确认服务器是其声称的身份,且客户端正在与该域的实际所有者进行交互。
- 预主密钥:客户端发送premaster secret,这个密钥是使用公钥加密的,只能通过服务器私钥解密。
- 私钥被使用:服务器解密预主密钥。
- 生成会话密钥:客户端和服务器均使用client random server random premaster secret生成共同的会话密钥。
- 客户端就绪:客户端发送已完成消息(会话密钥加密)。
- 服务器就绪:服务器发送已完成消息(会话密钥加密)。
- 实现安全对称加密:实现双方会话密钥加密通信。
- TLS1.3更快更安全:客户端问候-服务器生成主密钥-服务器问候完成-客户端验证生成主密钥发送完成-实现安全对称加密。
在发送真正的请求内容之前还需要三次↑往返服务器。
发送HTTP请求
浏览器发起读取文件的初始HTTP GET请求
响应
服务器响应请求并返回结果
服务器对浏览器请求做出响应,并把对应的html文件发送给浏览器
慢启动 / 14KB规则
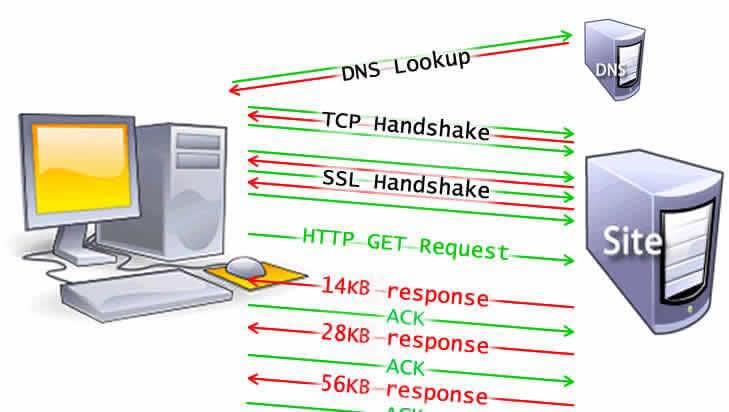
慢启动是一种衡量网络连接速度的算法,通过逐渐增加发送数据的数量来达到网络的最大带宽。

一般情况下,初始包是是个数据包,大约14K,第二次28K,第三次……成倍递增,直到达到最大带宽或者遇到拥塞。
拥塞控制
ssthresh - slow start threshold 慢启动门限 cwnd拥塞窗口 swnd发送窗口
慢启动:发送方每收到一个ACK,拥塞窗口cwnd对应增加,一般是指数增加。当到达门限sst(最大带宽)时,就开始拥塞避免了。
拥塞避免:发送方每收到一个ACK,cwnd+1,线性。
拥塞发生:网络出现拥塞了,发生数据包重传。若发生超时重传
这个时候
sst=cwnd/2 cwnd=1。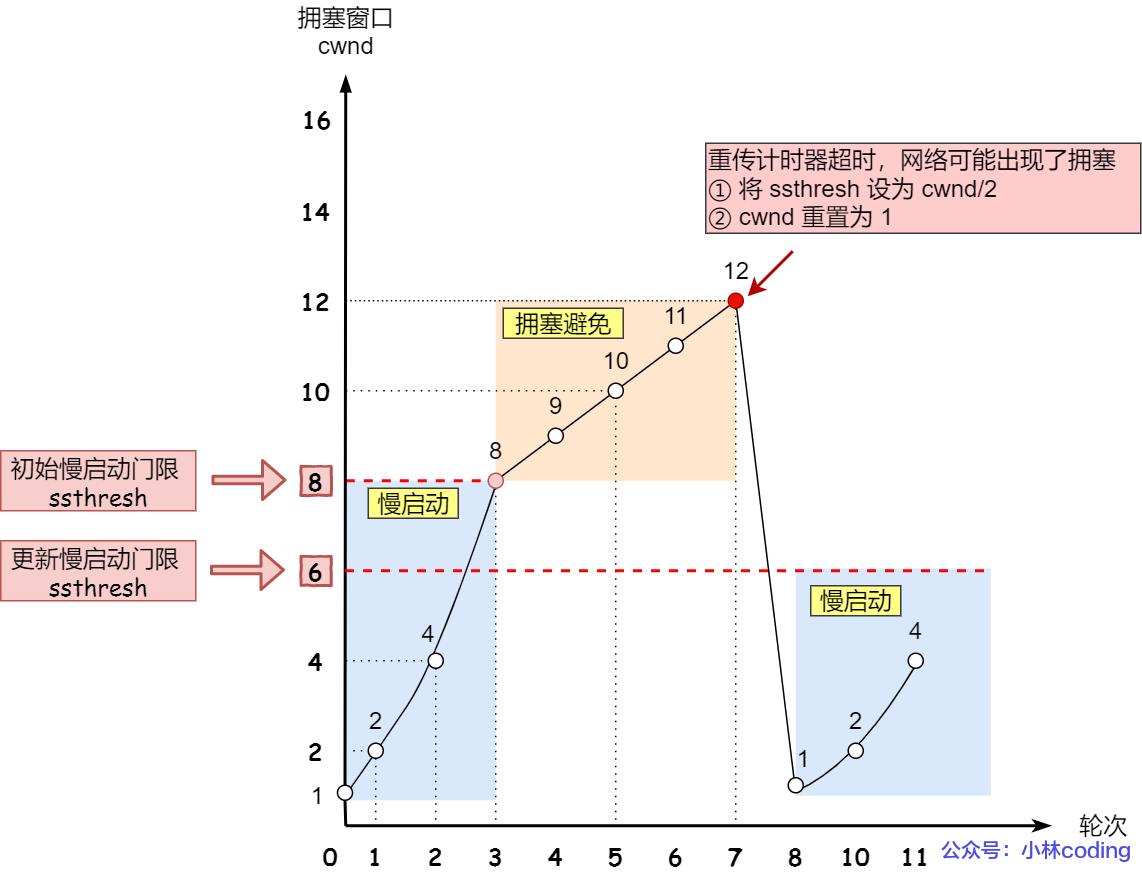
快速恢复:快速恢复一般和快速重传搭配使用。相比起超时重传慢开始,快速重传认为当接收方丢掉一个中间包时,发送三次前一个包的ACK,发送方会重新快速重传,不必等待超时重传。
此时
cwnd /= 2 sst = cwnd,随后进入快速恢复算法,cwnd = sst + 3-重传丢失包-若再收到重复ACK,cwnd ++-收到新数据时,可以接受正常数据了,恢复回cwnd = sst-随及进入拥塞避免状态。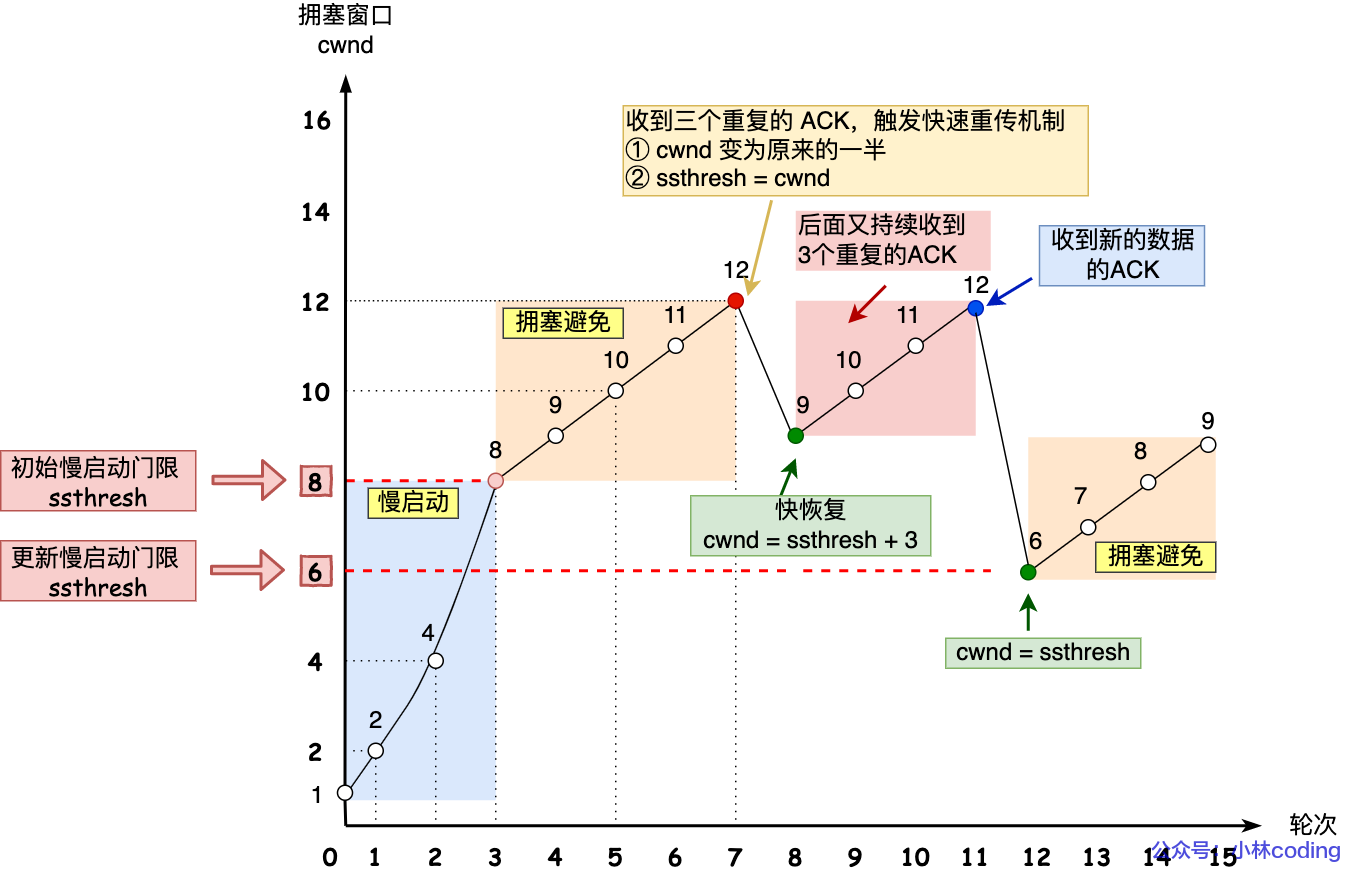
关于重传,有快速重传和超时重传两种,两者使用的拥塞发生算法是不一样的↑
其他:关于重传
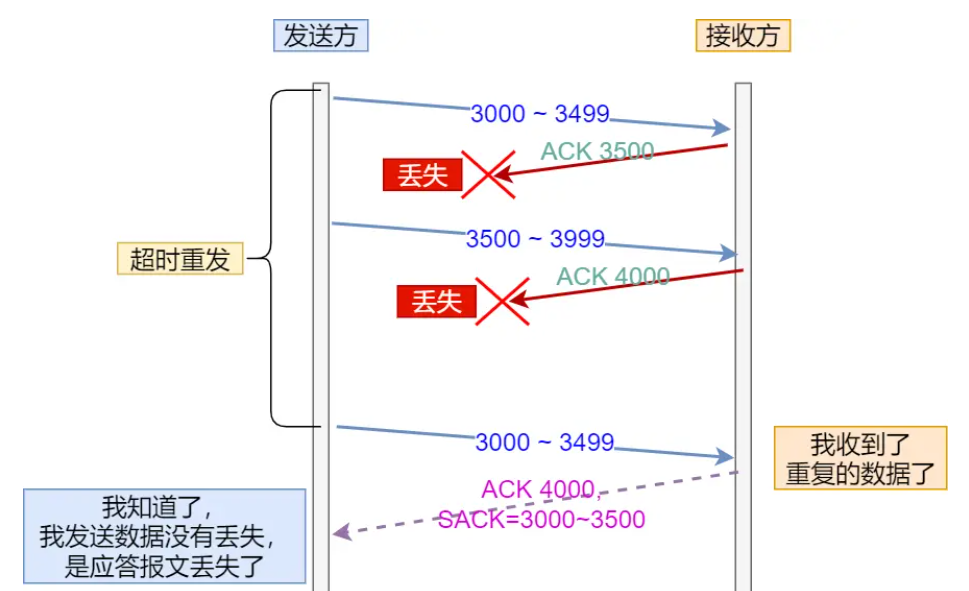
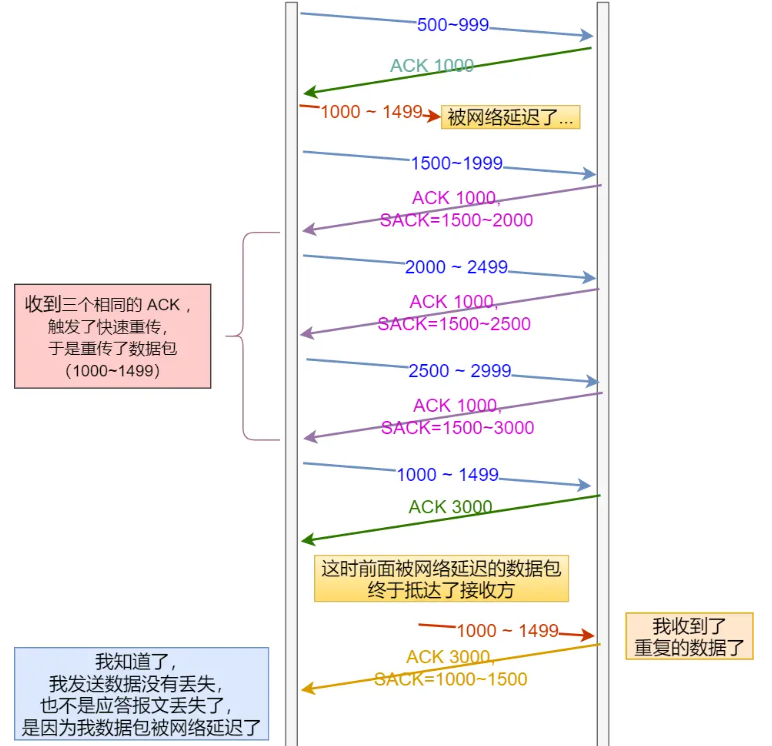
常见的重传机制:超时重传、快速重传、SACK、D-SACK
超时重传:发送数据时设计一个定时器,超过指定的时间后没有收到ACK报文,那就回重新发送数据。
快速重传:发送端发送数据过程中意外丢失了一个数据包,随后,发送端连续接收了三次相同ACK报文,此时开启快速重传,随后快速回复。有个问题:重发丢失数据包后接着哪个包发送?如果连续丢失了俩,如果已经发了很多后续包……
SACK:Selective Acknowledgment,选择性确认。在TCP头部添加SACK字段,用来记录发送已经收到了哪些数据信息。使得当发生包丢失的时候,只重传丢失的数据。这个重传机制需要发送接收双方都支持才可哦。
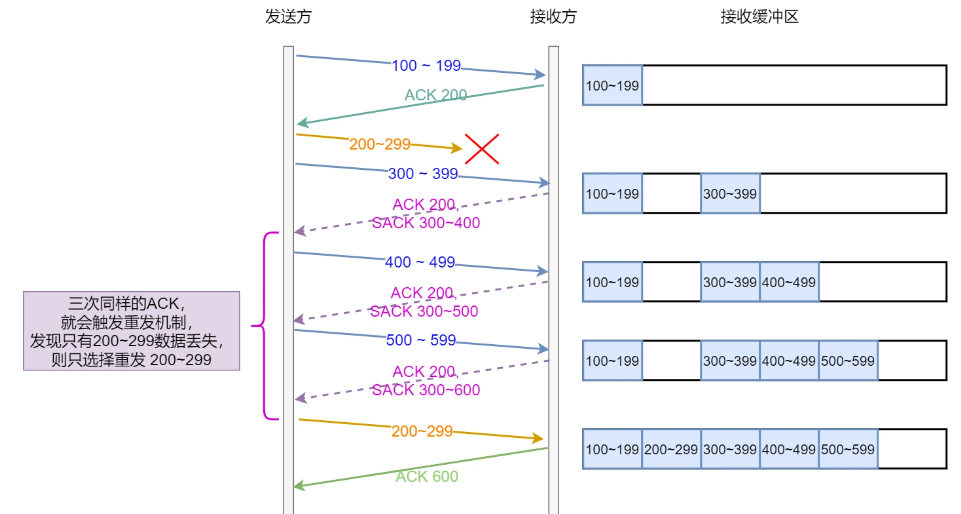
D-SACK:Duplicate SACK,重复。SACK存放的是接受重复的数据。使得发送方可以接收到反馈来的具体情况。
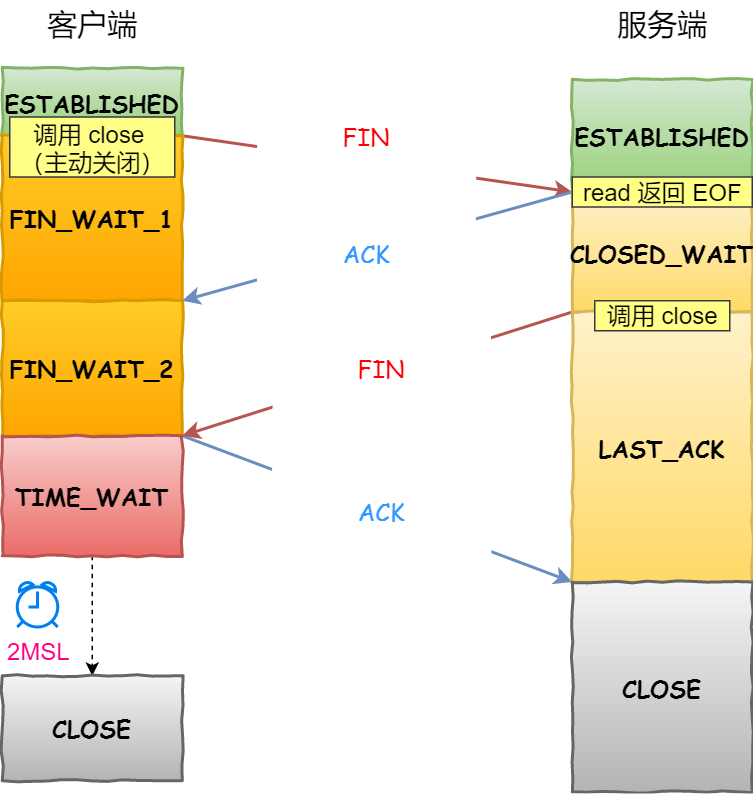
关闭TCP连接
TCP四次挥手
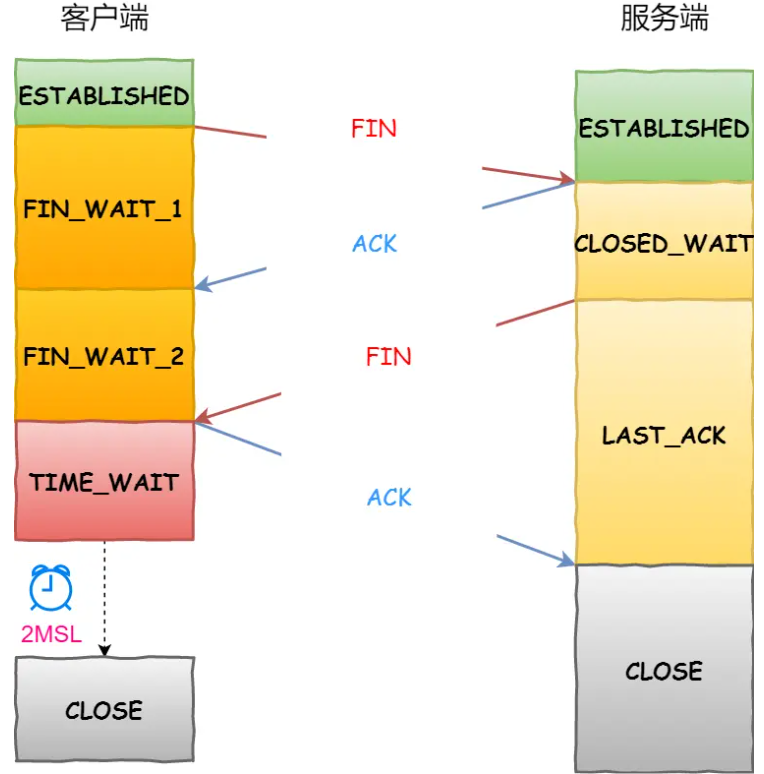
- 第一次:客户端向服务端发送TCP首部标志
FIN=1的报文,之后进入FIN_WAIT_1状态 - 第二次:服务端收到FIN报文,向客户端返回
ACK报文,之后进入CLOSED_WAIT状态,客户端收到后变为FIN_WAIT_2状态 - 第三次:服务端向客户端发送
FIN报文,之后进入LAST_ACK状态 - 第四次:客户端收到FIN报文,向服务端发送
ACK报文,之后进入TIME_WAIT状态,服务端收到后CLOSE,客户端一段时间(2MSL)后自动进入CLOSE状态。
MSL是网络中数据包最长的生存时间,大概两分钟
FIN报文不管是进程正常退出也好异常退出也好,服务器内核都会发送FIN报文,完成四次挥手
粗暴关闭&优雅关闭
关闭连接函数相关。关闭连接的函数有两种↓
close函数:同时socket关闭发送方和读取放,这个方法使得直接关闭发送数据和接收数据的能力。如果有多进程/线程共享同一个socket,其中一个进程调用了close,那么socket引用计数将-1,当计数减为0时,才会发送FIN报文。
shutdown函数:可指定socket只关闭发送方向,不关闭读取方向,数据能收不能发了。如果有多个进程/线程共享同一个socket,管你几个,直接关关关!直接发FIN!
粗暴关闭
如果客户端用↑close函数关闭连接,那么在四次挥手过程中,客户端一旦又收到了服务端发送的数据,客户端会直接返回一个RST报文给服务端,解释自己已经没有收发数据的能力了,赶紧关闭吧,然后服务器内核就会释放掉连接,直接close掉。
此外,这个close函数使得FIN_WAIT_2状态等待时间是有限的,所以过了等待时间tcp_fin_timeout,也就关掉了。
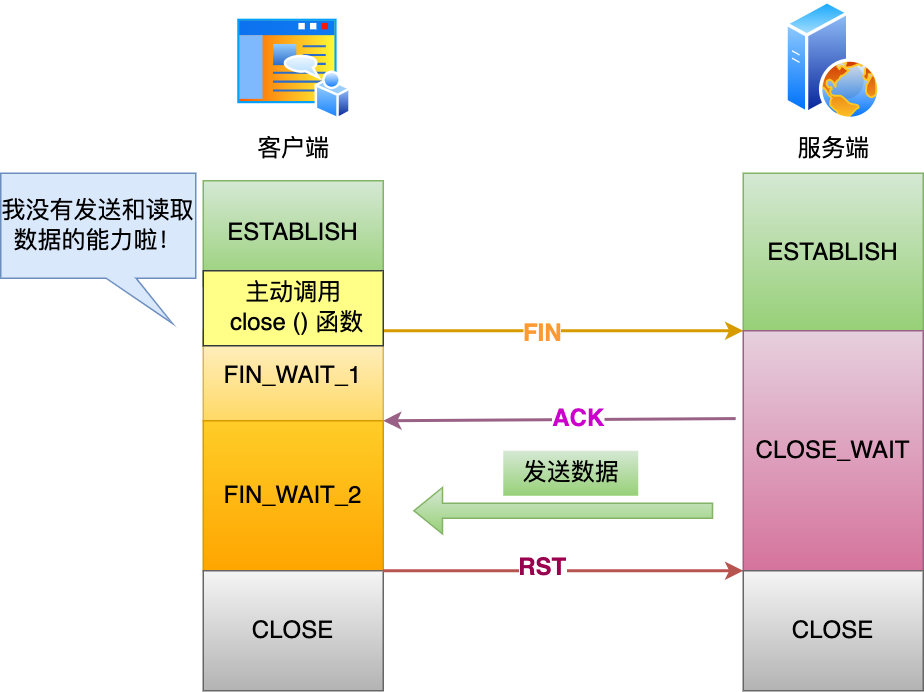
优雅关闭
就是↓这样子的四次挥手了。用的shutdown函数,客户端还能正常读一下数据,然后才关关。这里FION_WAIT_2状态等待时间是没有限制的,等不到死等。
为啥是四次?
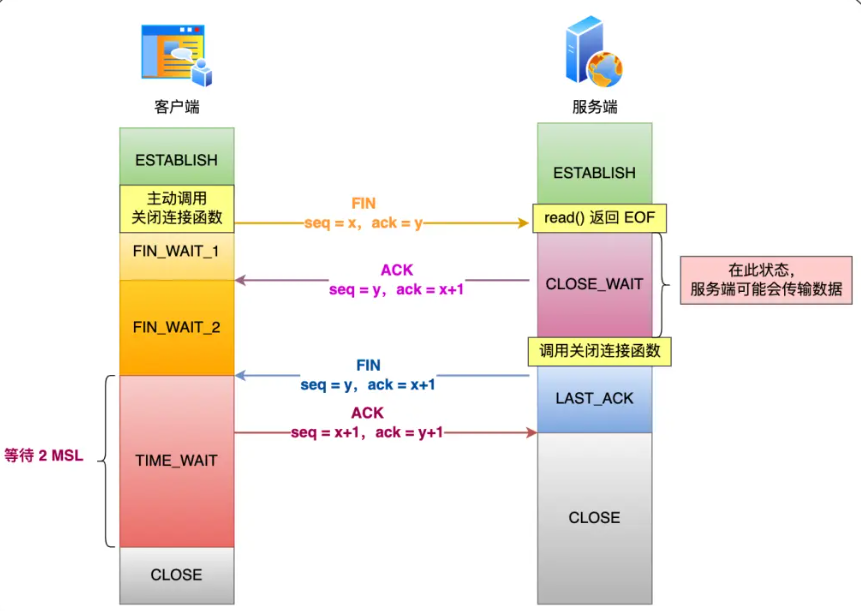
- 关闭连接的时候,客户端向服务端发送FIN报文的时候,仅仅代表客户端不再发送数据了,但是还是会收到数据的。
- 服务器收到报文之后,先回答一个ACK,随后服务端可能(还有一些未完全处理的数据需要发给客户端或者数据还没传完)(等待一段时间使得客户端有一定时间获取到ACK报文,一般也是2MSL),这几种情况完事儿之后,会再发一个FIN表示服务器不会再向客户端发送数据了。
- 客户端收到FIN报文后就可以给服务端发一个可以关闭了的消息了。
四次挥手可不可以变成三次挥手?
可以,抓包的时候会有抓到这种三次挥手包的情况。也就是ACK和FIN合并成一条从服务器发送到客户端。
那么什么情况下才会出现三次挥手呢?
没有数据需要发送或者正在发送了+开启了TCP延迟确认机制。
啥又是“TCP确认机制“?
当发送没有携带数据的ACK报文的时候,它的网络效率是很低的。为了解决这个问题,衍生出来了这个确认机制。策略如下↓
- 当有响应数据发送的时候,ACK会带着数据麻溜发送给对方
- 当没有响应数据发送的时候,ACK会延迟一段时间,等待是否有响应数据一起发送,如果没有那还是要发的
- 如果延迟等待发送ACK期间,第二个数据报文又到达了,那还是赶紧发过去ACK报文吧
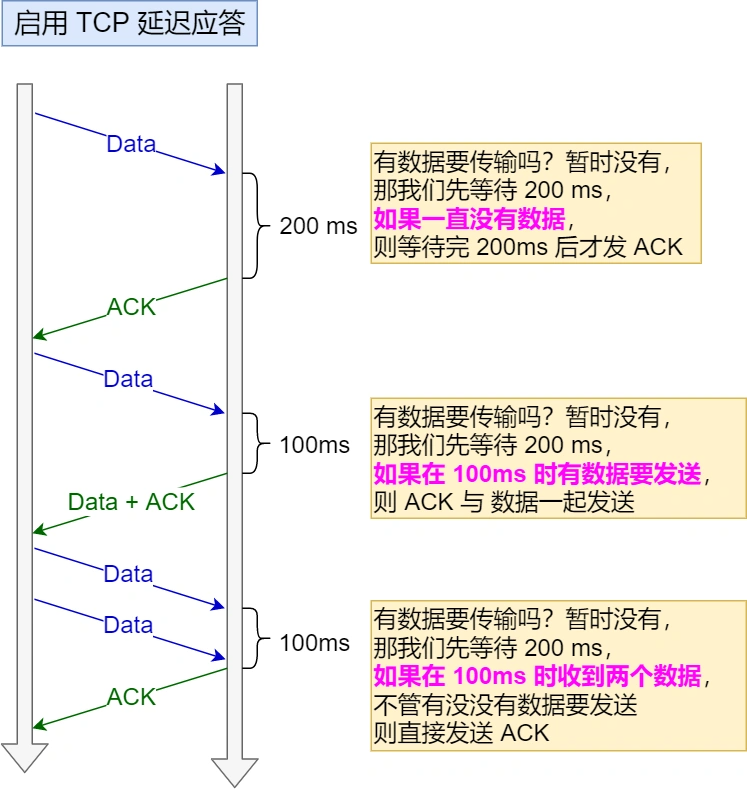
每个系统这一块基本都有一个最小延迟时间和最大延迟时间,和系统的时钟频率相关。HZ/25 HZ/5
关闭TCP延时确认机制:
1 | // 1 表示开启 TCP_QUICKACK,即关闭 TCP 延迟确认机制 |
第一次挥手无会发生啥
客户端重传重传重传,到限了,关了;服务器一直开着。
第二次无
客户端重传重传重传,到限了,关了;服务器一直CLOSE_WAIT。
第三次无
服务端重传重传重传,到限(tcp_orpha_retrie)了,从LAST_ACK变为关了;
客户端一直CLOSE_WAIT_2,倘若客户端这边使用的是close函数,那么过一会儿关了,如果是shutdown函数,那么死等了。
第四次无
服务器以为服务端没收到,重传重传重传,到限了,关了;
客户端每次收到服务器FIN都会重置一次2MSL定时器然后回复ACK,无奈ACK一直到不了,最后服务器已经关了,那这边等等也就关了。
为啥TIME_WAIT等待时间是2MSL??
MSL-maximum segment lifetime报文最大生存时间,它是任何报文在网络上存在的最长时间,超时这个报文就会被丢弃。
众所周知TCP协议是基于IP,协议的,IP头中有TTL字段,该字段是IP数据报可以经过的最大路由数,路过一个路由器-1,直到0,数据报被丢弃,同时发送ICMP报文通知源主机。
MSL>=TTL消耗到0的时间
之所以2MSL,有一种解释是数据报发过去还需要等接收方返回来一个确认报文,一来一回所以是两倍。
为啥有TIME_WAIT这个状态环节??
- 主动发起关闭的一方才会有这个状态
- 防止历史连接中的数据被后面相同四元组的连接错误接收
- 保证被动接收连接的一方能够正确关闭
↑过多会有啥危害?
- 客户端:如果状态过多,客户端占满了所有的端口资源,那么就无法对目的IP&PORT相同的服务端发送连接了。当然被使用的端口还是可以向其他不同的服务端发送连接的。客户端的端口是可以复用的。
- 服务端:由于服务端只监听一个端口,且一个四元组唯一确定一个TCP连接,所以服务端可以建立很多连接。但是状态过多,TCP连接过多的话,会占用系统资源。
↑如何优化它?
↑服务器大量出现它的原因?
了解它需要了解何时服务器才会主动断开连接。
- HTTP没有使用长连接(两方请求头均有Connction: Keep-Alive,有一个是close就完蛋),每次请求都需要建立TCP-请求资源-响应资源-释放连接。那么在频繁四次挥手的过程中,就会有TIME_WAIT。
- HTTP长连接超时(长连接有一个特点,如果没有一方提出断开,那么连接一直存在),服务端通常给长连接设置
keepalive_timeout参数。也就是说在连接中处理好一次请求后,若这段时间内没有再次发起新请求,那么出发回调函数来关闭连接,这时候服务端就会出现这个状态。 - HTTP长连接的请求数量达到上限,服务端通常给一条HTTP长连接设置一个最大能处理请求的数量
keepalive_requests,当数量达到时,会主动关闭连接,那么这个时候服务端也会出现这个状态。
服务器大量出现CLOSE_WAIT状态原因?
- 被动关闭方才会有的状态。如果被动方没有调用close函数关闭连接,那么将无法FIN报文发出,那么就不会变为LAST_ACK状态。反过来,如果服务器出现大量该状态,说明服务器没有调用close函数关闭连接。因此,我们可以分析什么情况不会调用close函数↓
- 具体原因参照服务端TCP流程
如果已经建立了连接但是客户端突然故障咋办?
如果连接成功了,客户端突然因为一些原因故障了,那么这个时候要是服务端一直不发送数据给客户端,服务器是无法感知客户端故障的。为了避免这种情况,TCP建立了一种保活机制↓
定义一个时间段,在该时间段内,如果没有任何连接相关的活动,那么保活机制开始作用,每隔一段时间发送一个探测报文(数据量很少),如果连续几个探测报文都没有得到回应,那么判定当前TCP连接死亡,系统内核向上层应用程序发送错误通知信息。
1 | 保活时间net.ipv4.tcp_keepalive_time |
开启保活机制无非三种情况:
- 对端正常,探测报文能被正常响应,此时TCP保活时间会被重置
- 对端宕机然后重启了,赶上了探测报文的发送,但是这个时候对端是没有什么连接信息的,所以给服务端返回了RST报文。此时TCP连接被发现重置
- 对端宕机了,TCP保活探测信息无法抵达,没有任何响应,那么达到最大保活探测次数后,确认TCP连接死亡,并上报。
真的好强,好多知识点啊!由于保活时间较长,可以在应用层自行实现一个心跳机制。一般服务器软件都会提供keepalive_timeout参数来确定HTTP长连接时间,时间一超,就启动一个定时器,定时器时间一到,直接触发回调来释放连接。
↑服务器突然故障咋办?
之前有提到过,无论服务器正常断开连接还是非正常断开连接,都不会影响内核发送FIN挥手以及后续挥手过程的正常进行。
解析渲染-浏览器渲染
客户端(浏览器)解析HTML内容并渲染出来,浏览器接收到数据包后的解析流程为:
- 构建DOM树:词法分析然后解析成DOM树(dom tree),是由dom元素及属性节点组成,树的根是document对象
- 构建CSS规则树:生成CSS规则树(CSS Rule Tree)
- 构建render树:Web浏览器将DOM和CSSOM结合,并构建出渲染树(render tree)
- 布局(Layout):计算出每个节点在屏幕中的位置
- 绘制(Painting):即遍历render树,并使用UI后端层绘制每个节点。
CRF
关键渲染路径CRF(Critical Rendering Path),指浏览器渲染网页时所执行的一系列关键步骤。包括服务器请求响应、加载、执行脚本、渲染、布局、绘制每个像素到显示屏等。(浏览器部分性能优化也是在这些方面优化)
DOM
文档对象模型。它是增量的,包含页面所有元素。HTML文件响应变成令牌token,令牌编程节点,节点编程DOM树。
单个节点从startTag令牌开始到endTag令牌结束,节点包含HTML元素的所有信息。节点根据令牌层次结构连接到DOM树中。节点数越多,关键路径后续事件的花费就越长。
CSSOM
样式对象模型。它不是增量的,它是级联的,包含页面所有样式。解析CSS过程中根据样式规则和选择器,将对应的样式属性添加到CSSOM中。
CSSOM使得JS可以通过DOM接口来修改页面样式。CSS是渲染阻塞的,浏览器会阻塞页面渲染直到接收执行了所有CSS完成CSSOM才会渲染内容。CSS之所以是阻塞渲染的是因为规则可以被覆盖。CSSOM随着CSS解析逐渐构建,直到完成都不能被用来构建渲染树,因为样式将会被之后的解析所覆盖,而不是渲染到屏幕上。换句话,CSSOM没有构建完成,RenderTree不会开始构建。
RenderTree
渲染树。浏览器从DOM根节点开始检查每个节点,决定哪些CSS规则被添加,最后形成一个DOM和CSSOM的结合体。
渲染树只包含可见内容,例如如果有一个元素的display: none,那么这个元素以及其后代均不会出现在渲染树中。
布局
页面布局。布局决定了如何在页面中放置元素,以及这些元素的宽高和元素间的相关性。
布局取决于屏幕尺寸,布局性能受DOM影响,节点越多,布局花费时间更长。因此,为了而减少布局事件的频率和时长,应尽量避免改动盒模型,或者批量更新。
绘制
一旦布局完成,像素就可以被绘制在屏幕上。若有改动将进行重绘等操作。
浏览器被优化为只重绘需要重绘的最小区域。计算布局+重绘这两个是绘制环节优化的重要方面,而不是关注样式属性的增加和移除。因为前者计算布局并绘制花费时间比单纯移除一个样式属性花费时间要更加明显。进行性能优化的时候要先测量确定布局重绘的时间开销,确定好性能瓶颈所在。
拓展:CRF优化
- 异步、延迟加载、消除非关键资源的请求数量
- 优化必须的请求数量和每个请求文件的体积
- 区分关键资源的优先级来优化被加载资源的顺序,缩短关键路径的长度
回顾:CSS根据什么样的规则生成
- 规则集RuleSet:由选择器和一组样式组成
- 样式规则的组织:CSSOM样式规则类似树状结构,根节点是文档根节点,其他规则集成为各子节点
- 嵌套规则:一个规则集包含另一个规则集
- 样式属性:有些样式是可以继承的,有些不能被继承
- 选择器权重:权重越高优先级越高,相同权重看后一个
- !important
- 1000 内联样式:在元素的style中定义
- 0100 ID选择器:通过元素id属性定义
- 0010 类选择器/属性选择器/伪类选择器:class/[type=1]/:hover
- 0001 元素选择器/伪元素选择器:p,div/::before,::after
1 | <div id="div1" class="container" style="color: white">啊啊啊啊啊</div> |
1 | #div1 { |

JS引擎解析过程
调用JS引擎执行JS代码(JS的解释阶段,预处理阶段,执行阶段生成执行上下文,VO,作用域链、回收机制等等)
- 创建window对象:全局执行环境在页面产生时就被创建,所有的全局变量和函数都属于window的属性和方法,而DOM Tree也会映射在window的doucment对象上。当关闭网页或者关闭浏览器时,全局执行环境会被销毁。
- 加载文件:完成js引擎分析它的语法与词法是否合法,如果合法进入预编译
- 预编译:在预编译的过程中,浏览器会寻找全局变量声明,把它作为window的属性加入到window对象中,并给变量赋值为’undefined’;寻找全局函数声明,把它作为window的方法加入到window对象中,并将函数体赋值给他(匿名函数是不参与预编译的,因为它是变量)。而变量提升作为不合理的地方在ES6中已经解决了,函数提升还存在。
- 解释执行:执行到变量就赋值,如果变量没有被定义,也就没有被预编译直接赋值,在ES5非严格模式下这个变量会成为window的一个属性,也就是成为全局变量。string、int这样的值就是直接把值放在变量的存储空间里,object对象就是把指针指向变量的存储空间。函数执行,就将函数的环境推入一个环境的栈中,执行完成后再弹出,控制权交还给之前的环境。JS作用域其实就是这样的执行流机制实现的。
✅浏览器缓存机制-强制缓存和协商缓存
缓存机制
是什么
浏览器缓存机制是浏览器在访问网页时,将一些数据保存至本地的一种技术。
为什么
我们都知道浏览器和服务器之间的通信是基于两者建立连接的。两者建立连接通常会耗费一定时间。很多响应是需要浏览器与服务器多次往返通信才能形成一个完整的响应。这个过程中很有可能会增加访问服务器的资源成本。因此浏览器利用缓存机制,让浏览器可以重用一些响应数据,从而减少多次交互带来的资源占用。
具体解释
浏览器缓存的主要步骤:
- 在浏览器发出请求前,会先去到浏览器缓存中查看是否有对应的结果和缓存标识,如果有,很好,如果没有,向服务器发出请求。
- 服务器将相应结果和缓存标识返回给浏览器,浏览器根据响应头中的缓存标识决定是否将结果和标识存入缓存。
浏览器缓存机制分为强制缓存和协商缓存,两者相互配合完成任务:
强制缓存:浏览器向浏览器缓存中查询请求结果,并根据缓存规则决定是否使用该缓存结果。
控制强制缓存的字段:Cache-Control > Expires(废弃)
Cache-Control: max-age=100,s-maxage=200,public
- 不存在缓存结果和缓存标识:强制缓存失效,直接发出请求
- 存在但缓存结果失效:强制缓存失效,使用协商缓存
- 存在且有效:强制缓存生效,直接返回结果
协商缓存:浏览器向服务器发送携带缓存标识的请求,服务器根据缓存标识决定是否使用该缓存。
控制协商缓存的字段:Etag / If-None-Match > Last-Modified / If-Modified-Since
a. 在服务器端读出文件修改时间,将读出的修改时间赋给lastmodified,cachecontrol设置nocache。次访问时,会有ifmodifiedsince,值为次修改时服务器给它的时间。
b. Etag比较文件指纹。首次请求,服务器将读取目标文件计算出的文件指纹放响应头etag字段。二次请求,客户端读取Etag,赋给ifnonematch字段,让上次文件指纹跟随请求一起去到服务端。服务端拿到idnonematch字段后再次读取目标资源并生成文件指纹,俩指纹做对比,如果完全一致,返回304,如果不同,返回新的Etag。
c. 第二种方式优点()缺点(计算开销、服务器性能、弱验性-提取文件部分属性生成哈希值-快但准确率不高-降低协商缓存有效性)
- 协商缓存生效:返回304
- 协商缓存失效:返回200+请求结果
哪些是强缓存哪些是协商缓存
所有带304的资源都是协商缓存,所有标注(从内存读取/从磁盘读取)的资源都是强缓存。
✅前端如何实现缓存资源
前端之所以缓存是为了减少不必要的网络传输,加速页面加载,减少服务器负载。
前端缓存主要分为浏览器缓存和http缓存。
1.http缓存
http缓存是web前端缓存的核心。↑
2.浏览器缓存
| 比较 | Cookie | localstorage | sessionstorage | Indexed_db |
|---|---|---|---|---|
| 定义 | 一种存储在客户端的小型文本文件。 | H5提供的一种在浏览器端本地存储数据的机制。 | H5提供的一种在浏览器端存储会话数据的机制。 | 浏览器提供的JSAPI,用于在浏览器存储和查询结构化的数据。异步、对象存储、妥妥的数据库 |
| 存储位置 | document.cookie(浏览器的cookie文件夹) | localStorage | sessionStorage | indexedDB.open() db.createObjectStore() add()或 put() get()或 getAll() close() |
| 大小 | 4KB | >=5MB | >=5MB | 大得多 |
| 生命周期 | 默认会话,可设置 | 永久,除非手动清除或过期 | 会话 | 永久,除非操作删除 |
| 场景 | 身份验证和会话管理、用户偏好、跟踪用户行为 | 用户首选项、会话状态、本地缓存、应用程序配置、计数器和标记 | 表单数据临时存储、会话状态、临时缓存 | 大量结构化数据、离线应用、复杂的数据查询、数据索引、日志记录 |
Cookie
少量缓存。它由服务器在http响应中设置,保存在浏览器中,每次请求同一个服务器的时候,将Cookie发送回服务器。
在PaperTODO中我们有用到NextAuth,其中用户登录后拿到的token就是存在cookie中的。
1 | // 设置一个 Cookie |
LocalStorage
一种本地存储方案。少量缓存
将一些数据存储到本地存储中,相当于在本地缓存了一些数据,使得在下一次打开网页时的快速访问。
1 | localStorage.setItem(key, value) // + |
SessionStorage
一种本地存储方案。少量缓存
将一些数据存储到会话存储中,相当于在会话范围内存储一些数据,方便在会话内快速访问。
1 | sessionStorage.setItem(key, value) |
3.ServiceWorker
是一个独立的浏览器特性,用于实现一种浏览器和网络代理之间的代理层。它允许开发者拦截和处理网络请求,从而实现离线缓存、推送通知、拦截请求并返回自定义响应的功能。
特点
- 它是一个JS线程,运行在浏览器后台,独立于页面
- 充当网络代理,可以拦截和控制请求和响应
- 只在HTTPS网站上工作,避免恶意注入和拦截敏感数据
- 离线缓存、数据预取、消息推送
场景
- 离线缓存
- 数据预取/预加载
- 响应拦截和修改
- 推送通知
浏览器后台脚本,可以拦截网络请求并进行缓存管理,通过使用它,可以实现更加灵活的缓存策略。
1 | // 在Service Worker脚本中实现缓存 |
✅什么是内存泄露,哪些情况会造成/如何查看泄露情况?
内存泄露指程序中内存资源被无法访问的对象占用,导致这些内存资源不能被垃圾回收,最终导致程序占用的内存不断增加,可能导致程序性能下降崩溃。
内存泄漏往往由程序中一些错误和不良编程实践导致。
- 未释放对象引用
- 未关闭资源
- 事件监听器未移除
- 大量缓存数据
- 循环数据结构
查看泄露情况(说实话我不大会这个)。
- 浏览器开发者工具
- 内存分析工具
- 代码审查
- 使用性能分析工具
✅JS垃圾回收(Garbage collection)机制
在计算机编程中,查找删除一些不被其他对象引用的对象处理过程。
项目中,如果存在大量不被释放的内存(堆/栈/上下文),页面性能会变得很慢。当某些代码操作不能被合理释放,就会造成内存泄漏。我们尽可能减少使用闭包,因为它会消耗内存。
浏览器垃圾回收机制/内存回收机制:
浏览器的
Javascript具有自动垃圾回收机制(GC:Garbage Collecation),垃圾收集器会定期(周期性)找出那些不在继续使用的变量,然后释放其内存。标记清除:在
js中,最常用的垃圾回收机制是标记清除:当变量进入执行环境时,被标记为“进入环境”,当变量离开执行环境时,会被标记为“离开环境”。垃圾回收器会销毁那些带标记的值并回收它们所占用的内存空间。谷歌浏览器:“查找引用”,浏览器不定时去查找当前内存的引用,如果没有被占用了,浏览器会回收它;如果被占用,就不能回收。
IE浏览器:“引用计数法”,当前内存被占用一次,计数累加1次,移除占用就减1,减到0时,浏览器就回收它。
优化手段:
内存优化,避免过多全局变量 ;
手动释放引用,用不到的手动设置为null等;
合理使用闭包,少一点闭包,多一点内释放;
避免循环引用,循环引用指两个或多个对象相互引用,这导致无法被访问,无法被垃圾回收;
使用对象池,预先创建一个对象,这个对象可以被复用,在需要创建大量临时对象时可减少回收负担;
性能优化循环,避免在大型循环中创建新对象,尽量还是复用对象,减少内存分配和垃圾回收次数;
使用RAF,代替延时器定时器,更好促进浏览器渲染引擎的协同工作,使得动画更加丝滑;
使用现代JS特性,尽量使用优化迭代后的新特性,而不是var/eval/with这类;
使用WebWorker,将大型计算等任务从主线程中分离出来,减少主线程垃圾回收对性能的影响;
监控和优化内存应用,使用F12内存工具监控页面内存使用情况,并进行针对性优化,及时优化。
常见的内存泄漏
- 主要:全局变量、闭包、定时器、DOM元素的引用
- 其他:未解除事件监听、循环引用、未释放的资源(请求等)、使用缓存不当、大对象的反复重用
✅浏览器存储
WebStorage、Cookie、indexedDB
具体见上方浏览器缓存。
✅存储 cookie的生命周期
创建
服务器通过HTTP响应头↓将一个新的Cookie发送给客户端
1 | Set-Cookie: username=JohnDoe; expires=Wed, 02 Aug 2023 12:00:00 UTC; path=/ |
存储
浏览器收到cookie后将其存入特定的文件夹中
1 | let cookie = document.cookie |
读取
当客户端向同一个服务器发送请求时,浏览器会检查该服务器的cookie,并将匹配的cookie添加到HTTP报文头中,服务器可以通过读取请求的cookie来获取客户端的信息。
1 | document.cookie = '....' |
过期
设置过期时间的cookie会在过期时间后过期,过期时间通过max-age/expires(废弃)设置
1 | Set-Cookie: username=JohnDoe; max-age=3600; path=/ |
删除
过期时间到达或者通过设置过期时间为过去的时间,可以使得cookie被删除
1 | document.cookie = "username=; expires=Thu, 01 Jan 1970 00:00:00 UTC; path=/;"; |
✅cookie安全
- cookie可能被禁用
- cookie是与浏览器相关的,不同浏览器存储的cookie是不同的
- cookie可能被删除
- cookie安全性不够高,所有cookie都是以纯文本的形式记录在文件中的,因此要适时进行信息加密
✅cookie 有哪些属性字段呢
name=value;键值对:每个网页最多一个cookie,每个cookie最多20个键值对,value长度不能超过4K。
domain=http://qvq.com;Domain域名:默认情况下用户访问网页的域名会存放在cookie,如果设置该值,代表域名上所有的服务器都可以访问该cookie,通常不能这样搞。
path=/login;目录路径:指定哪个目录的网页可以访问cookie。
expires=date.toGMTString();存活时间:默认情况下用户关闭浏览器cookie自动清除,若配置该值,设置GMT格式时间,cookie将在时间到期后过期。
secure=true/false;https发送cookie:true必须通过https发送cookie。
✅怎么不让前端去修改cookie?
- http-only:
http-only=true;限制cookie仅通过http/https请求发送到服务器,而无法通过JSdocument.cookie访问,防止大部分的XSS - same-site :
same-site=strict/lax;限制cookie仅在同一站点的请求中发送,防止跨站点请求伪造攻击CSRF - secure :
secure=true;使得只能通过https传输,防止在非加密连接上窃取cookie - 对cookie值进行签名:设置cookie时将cookie值与服务器生成的签名进行结合,并存储在cookie中,服务器在接收到cookie的时候先验证签名的有效性,防止cookie伪造
✅同源策略
定义
“同源”指的是==协议、主机、端口==相同的文档源。任何一个不同,就不是同源。
同源策略限制不同源之间的资源交互,这样做的原因是隔离开潜在恶意文件,从而提升资源交互的安全性。
继承
页面中所有的对象都继承其所属文档源。
文件源
使用file:///协议加载的文件被视为不透明来源,即 将本地文件视为来自一个特殊不安全的文件源。
处于安全考虑,若一个文件包括来自同一个文件夹下的其他文件,两者被认为不来自同一个源,CORS错误。
想要解决这个问题可以在本地开一个服务器,使用http://localhoost等自定义域名进行文件加载,避免CORS问题。
更改
在限定条件下,页面可以修改源↓
跨域数据存储和访问
每一个源都有自己单独的存储空间。WebStorage和IndexedDB都是以源划分存储的。
Cookie使用不同的源定义方式,也就是说,相比起cookie受同源策略限制的。
✅怎么解决跨域问题?
CORS跨域共享-优先-主要方案-双向-标准
通过服务器设置响应头部中CORS规则,允许其他域名的网页访问该服务器上的资源,包括cookie(设置一个白名单)。
1 | Access-Control-Allow-Origin: https://www.example.com |
1 | const express = require('express'); |
代理
该方法是将代理服务器作为浏览器和目标服务器的中间层,充当一个转发请求的角色。
vue脚手架、vite框架都会提供代理服务器,可以根据情况进行配置。
1 | // vue.config.js |
1 | // package.json |
postMessage-安全-不同窗口-加验证
在不同窗口或iframe之间,使用哪个该API进行跨域通信。该方式允许窗口间以安全的方式传递数据,跨源数据存储。
1 |
|
1 |
|
JSONP
使用script标签加载跨域资源,先创建一个回调函数,将回调函数名绑定在src里callback上,从而使得能在前端调用该函数。函数中带有获取到的数据作为入参,即可对参数做一些处理。可能会有XSS漏洞。
1 | <script> |
document.domain(弃用)
将该值设置为当前域或父域。
1 | document.domain = "qvq.com" |
缺点:
- 仅适用于子域名之间的跨域
- 无法处理不同端口号间的跨域
- 将其设置为顶级域名,影响子域安全性,很有可能收到XSS和CSRF攻击
- 用该方式解决跨域要求双方都要更改document.domain
✅script标签defer,async和没有标识的区别,加载情况,执行情况,对页面的阻塞情况
- 没有标识的情况:
- 默认情况下,如果不指定
defer或async属性,浏览器会按照<script>标签在页面中的顺序来加载和执行脚本。 - 这会导致浏览器在遇到脚本标签时立即停止渲染页面,开始下载并执行脚本,然后再继续渲染。
- 页面加载过程中,脚本的执行会阻塞后续 DOM 解析和渲染,直到脚本执行完毕。
- 默认情况下,如果不指定
defer属性:- 使用
defer属性的脚本会在 HTML 解析完毕后、DOMContentLoaded 事件之前加载和执行。 - 多个带有
defer属性的脚本会按照它们在页面中的顺序依次执行。 defer脚本不会阻塞页面的解析和渲染,因此页面可以继续渲染。
- 使用
async属性:- 使用
async属性的脚本会在下载完成后立即执行,而不会阻塞 HTML 解析。 - 多个带有
async属性的脚本也会并行下载,但不保证执行顺序。 - 由于脚本的执行是异步的,所以它们可能会在页面的 DOMContentLoaded 事件之前或之后执行。
- 使用
✅浏览器内核
浏览器内核是浏览器的核心组件,主要负责解析和渲染网页内容。
浏览器内核通常包括两个主要组件:
- 渲染引擎
- 负责解析三件,然后转换成网页内容
- DOM CSSOM → RenderTree → 像素
- JS引擎
- 解析和执行网页上的JS代码
- 交互
浏览器内核的工作方式是多线程的。主线程用于处理界面和渲染,其他线程用于网络请求、JS执行、其他后台服务(垃圾回收、处理文件、管理存储等)。
🖥️计网
五层模型
- 应用层:HTTP SMTP……
- 传输层:TCP UDP DNS TLS
- 网络层:IP
- 数据链路层
- 物理层
TCP/IP网络模型
| 各层 | 应用层 | 传输层 | 网络层 | 网络接口层 |
|---|---|---|---|---|
| 作用 | 用户所使用的各种应用软件 | 传输给对方数数据包,分块TCP段 | 传输IP报文,分片 | 封装数据帧 |
| 封装格式 | 应用数据 | TCP头-应用数据 | IP头-TCP头-应用数据 | 帧头-IP头-TCP头-应用数据-帧尾 |
| 协议 | HTTP/FTP/SMTP/DNS… | TCP/UDP | IP |
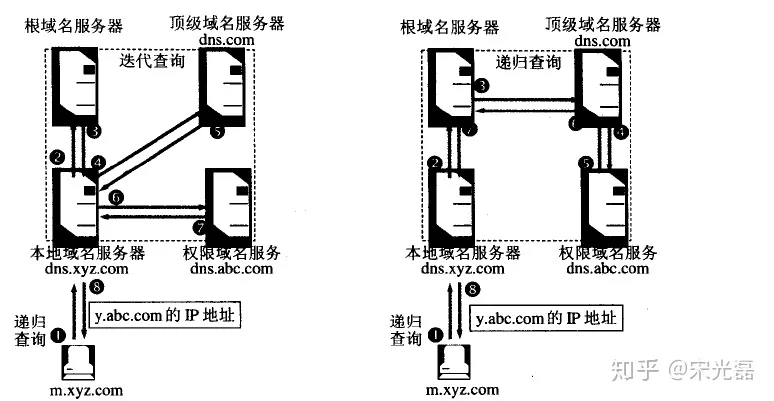
DNS解析域名的具体过程
迭代?递归?
HTTP
1 | graph LR |
基本概念
HTTP是超文本传输协议HyperTextTransferProtocol。
它是在客户端-服务端或服务端-服务端之间传输数据的约定和规范。
第二种之间的传输通信主要场景:
- 负载均衡:通过HTTP请求将请求发往不同的服务器,提高性能和可靠性
- 分布式系统:分布式系统需要各服务器间协调工作、共享数据、执行分布式任务,HTTP在此充当一种通信手段
- 数据同步:如果多个服务器存储着相同/相关的数据,可通过HTTP请求将数据同步到其他服务器,保持数据一致
- 微服务架构:微架构中不同的微服务可能运行在不同的服务器上,它们之间通过HTTP通信来完成服务之间交互
常见字段
Host→服务器域名
Content-Length←数据长度
Connection: Keep-Alive/close 长链接机制,只要任意一段不明确提出断开连接,则保持TCP的连接状态。
HTTP和TCP的keepalive不是一个登西!
前者由应用层实现,叫HTTP长连接
后者在TCP层,叫TCP保活
前者是解决HTTP频繁短连接(建立TCP连接-请求资源-响应资源-释放连接)而增加连接开销的问题,且为HTTP流水线(但是需要kepalive_timeout限制一下防止队头拥塞)提供可能。
后者是是一种TCP保活机制,如果两端TCP连接一直没有数据交互,那么就触发了TCP保活机制的条件,这时内核会发送探测报文。如果对端正常响应,无事;如果对端宕机,TCP会报告TCP连接死亡。socket接口设置SO_KEEPALIVE选项。
Accept→告知自己可接受哪些数据格式 e.g.Accept: */*
Content-Type←告知数据格式 e.g.Content-Type: text/html; Charset=utf-8
Accept-Encoding→告知能接受哪些数据压缩方法 e.g.Accept-Encoding: gzip deflate
Content-Encoding←说明数据压缩方法 e.g.Content-Encoding: gzip
🈯常见状态码
GET&POST
两者区别
| 区别 | GET | POST |
|---|---|---|
| 语义 | 从服务器获取指定资源 | 根据请求负荷(body)对指定资源做出处理 |
| 参数位置 | URL | body |
| 限制 | 请求参数:ASCII 浏览器对其URL长度有限制 |
任意格式,两方协商好即可 浏览器对其莫得大小限制 |
| RFC安全 | √ 只读操作,不会修改服务器上的数据 | × 会修改服务器资源 |
| RFC幂等 | √ 只读操作,服务器上数据安全,结果同 | × 多次提交数据会创建多个资源 |
| 可缓存 | √ 可以对GET请求的数据做缓存(浏览器/代理) | × 浏览器一般不会缓存POST请求,也不会将请求保存为书签 |
两者都是安全和幂等的吗?↑
根据RFC规范定义的两种方法看:
安全:请求方法不全不会破坏服务器上的资源
幂等:多次执行相同的操作,结果是相同的
但是实际开发中,开发者可能不会遵循以上规范,get也能post,post也能get,body谁都可以用,然而这样不好……
缓存技术
跳转:强制缓存/协商缓存
HTTP特性
HTTP/1.1优点
简单灵活易于扩展应用广泛跨平台
- 简单:Header+Body,Header:key-value
- 灵活益于扩展:提供各类请求方法、URL/URI、状态码、头字段等,允许自定义扩充
- 应用广泛跨平台:阿巴阿巴
HTTP/1.1缺点
无状态明文传输不安全
- 无状态:虽然服务器不会记忆HTTP状态,不需要额外资源记录状态信息,减轻服务器负担;但是一旦没有记忆能力,完成有关联性操作时会有些麻烦。怎么解决?Cookie!
- 明文传输:虽然方便阅读,带来极大便利;但信息裸奔
- 不安全:
- 使用明文传输:不加密,内容可能会被窃听
- 不验证通过对方身份:可能遭遇伪装
- 无法证明报文的完整性:可能被篡改
怎么办?HTTPS
HTTP/1.1性能
一般般,长链接管道网络传输队头阻塞
- 长链接:相比1.0,1.1有了长链接。
- 管道网络传输:在同一个TCP连接中发起多个请求,流水线式发送,减少整体响应时间。
- 队头阻塞:
- √ 请求的队头阻塞:服务器处理请求时耗时较长,后续请求会被阻塞
- × 响应队头阻塞
HTTP&HTTPS
区别?
- 前者是明文传输,后者是加密传输
- 前者连接相对简单,后者还需SSL/TLS握手(Secure Sockets Layer / Transport Layer Security)
- 前者默认端口80,后者433
- 前者免费,后者需要CA申请整数
HTTPS解决了HTTP哪些问题?
不再明文传输,而在HTTP和TCP层之间加入了SSL/TLS协议。信息不容易被窃取,网站有身份验证,内容有校验机制↓
- 混合加密保证机密性,解决窃听(对称加密和非对称加密混合)
- 通信建立前,使用非对称加密方式交换会话密钥。非对称需要公钥和私钥,公钥任意分发,私钥保密。交换速度较慢↓
- 通信过程中全部使用对称加密的会话密钥方式加密明文。只需一个保密密钥,运算速度快但不太安全↑
- 摘要算法+数字签名保证完整性,解决篡改(携带指纹传输)
- 先对内容计算出一个指纹,随内容一起传输给对端
- 对端拿到后也对内容计算出一个指纹,对比两个指纹是否一致,否则可能被篡改过
- !哈希算法虽可确保内容不被篡改,但不能保证不被中间人替换。因为缺少对客户端收到的消息是否来源于服务端的证明。为避免这种情况,可用非对称加密算法提供的公私钥解决,相互加解密。
- 公钥加密私钥解密:保证内容传输安全,只有持有私钥的才能解密(摘)
- 私钥加密公钥解密:保证消息不被冒充,若公正常解密出来,说明是对应端发来的(数)
- 服务器公钥放入数字证书中,防止冒充(CA颁布数字证书包裹公钥,身份验证,防止替换)
- 服务器将自己的公钥注册到CA
- CA用自己的密钥对该公钥进行签名,颁发数字证书
- 客户端拿到数字证书后用CA公钥进行确认
- 从证书中获取公钥后对报文进行加密
- 服务器拿到报文后用私钥解密
HTTPS是如何而建立连接的?期间交互了啥?
- ClientHello→支持的TLS版本,支持的加密算法,Client Random随机数
- ServerHello←确认的TLS版本,确认的加密算法,Server Random随机数,数字证书
- ClientResponse→根据CA公钥验证证书,拿到公钥,生成pre-master key,公钥加密,加密通信算法改变通知,握手结束通知
- ServerResponse←计算出会话密钥,加密通信算法改变通知,握手结束通知
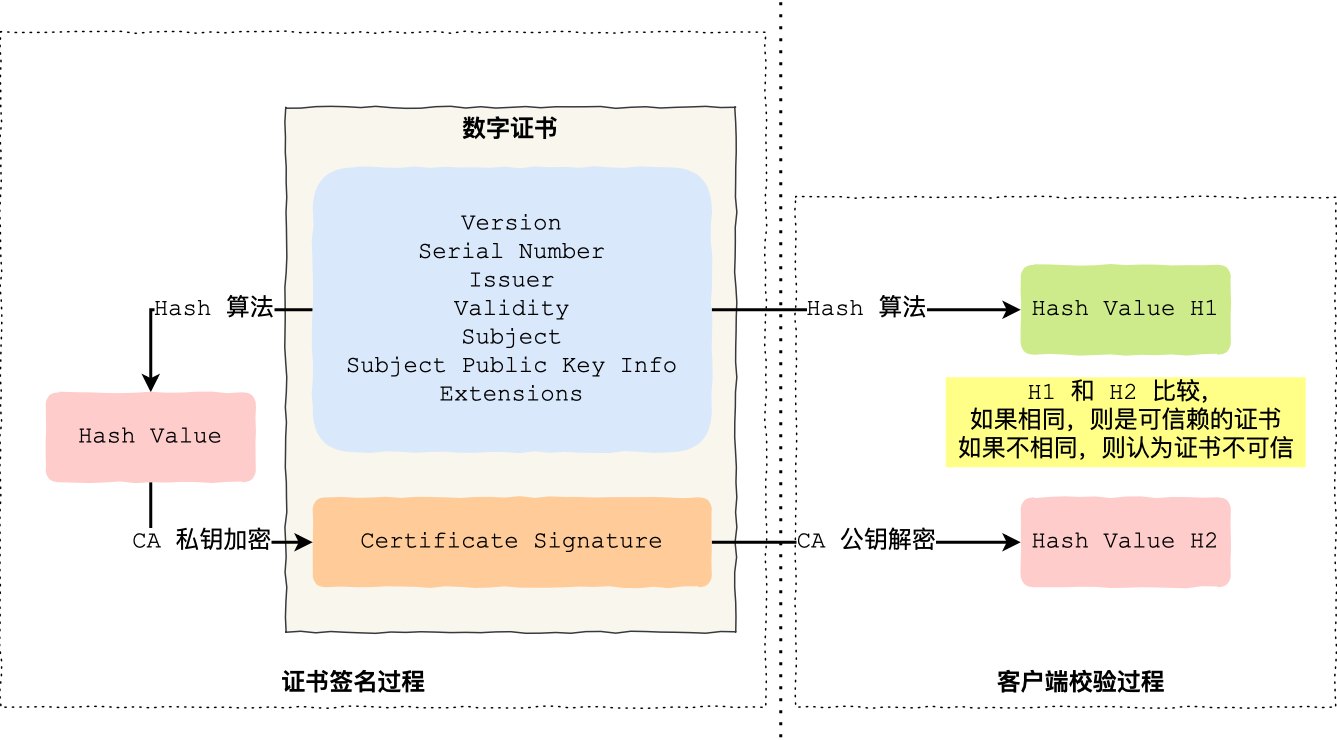
CA证书颁发过程:
- CA将持有者的公钥、用途、颁发者、有效时间等信息打包
- Hash算法计算得到一个值
- 用私钥加密该值,生成Certificate Signature(签名)
- 将签名添加到文件证书上,形成数字证书
校验过程:
- 使用同样的Hash算法获取证书,得到值
- 使用浏览器和操作系统继承的CA公钥信息去解密证书,得到值
- 两值比较,若值相同,可信赖;反之不可信
证书层级:
- 客户端收到证书后发现该帧数的签发者不是根证书,那么无法根据本地的公钥去验证。于是根据签发者找到证书颁发机构,请求中间证书
- 拿到证书后发现这个证书没有上级签发机构了,说明这个就是根证书,然后去验证。
- 这个可信的话,拿到了下层证书的公钥,然后验证。
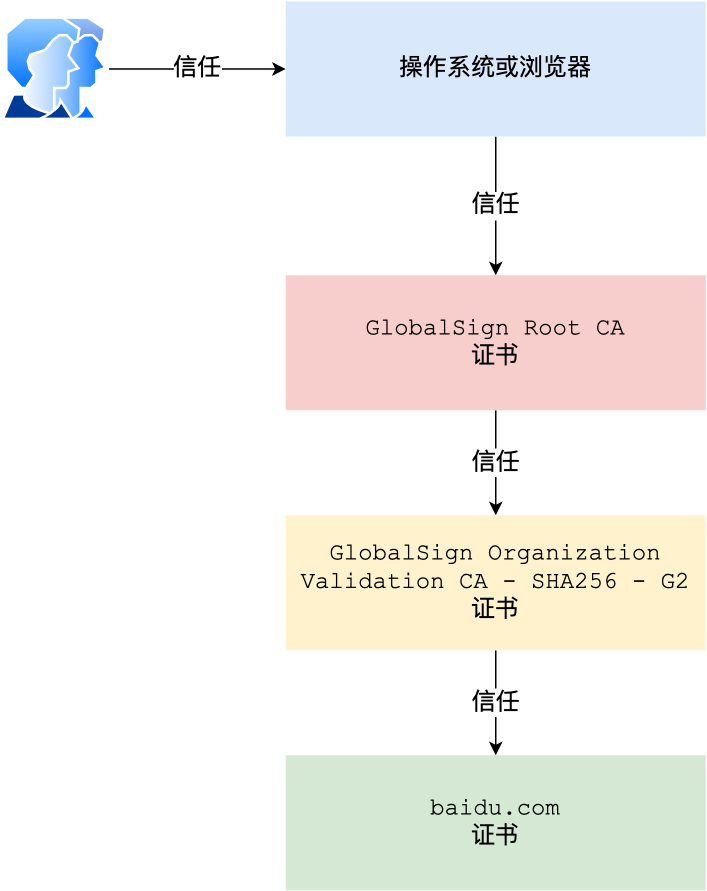
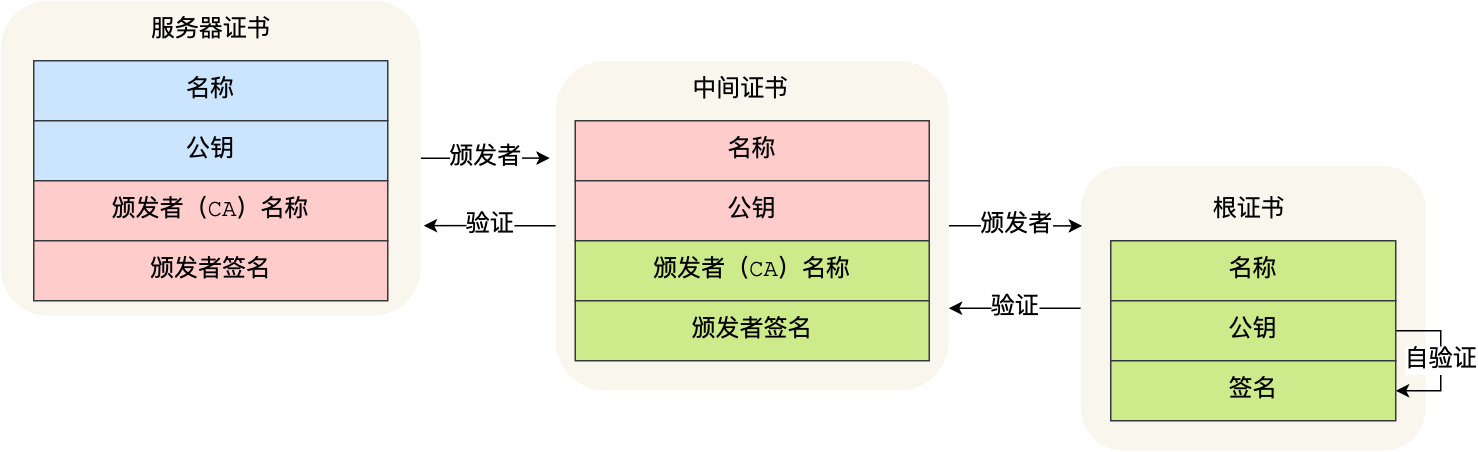
为何要形成一个证书链?——保证根证书的绝对安全性。
HTTPS应用数据是如何保证完整性的?
TLS分为握手协议和记录协议两层。
- 握手协议:四次握手期间,协商加密算法,生成对称密钥,保护HTTP数据
- 记录协议:数据交互期间,保护应用程序数据并返回完整性和来源
TLS记录协议消息压缩、加密、认证的过程
- 将消息分段
- 压缩片段
- 加入通过哈希算法计算出的消息认证码——Mac值
- 对称加密这段
- 加上数据的类型、版本、长度
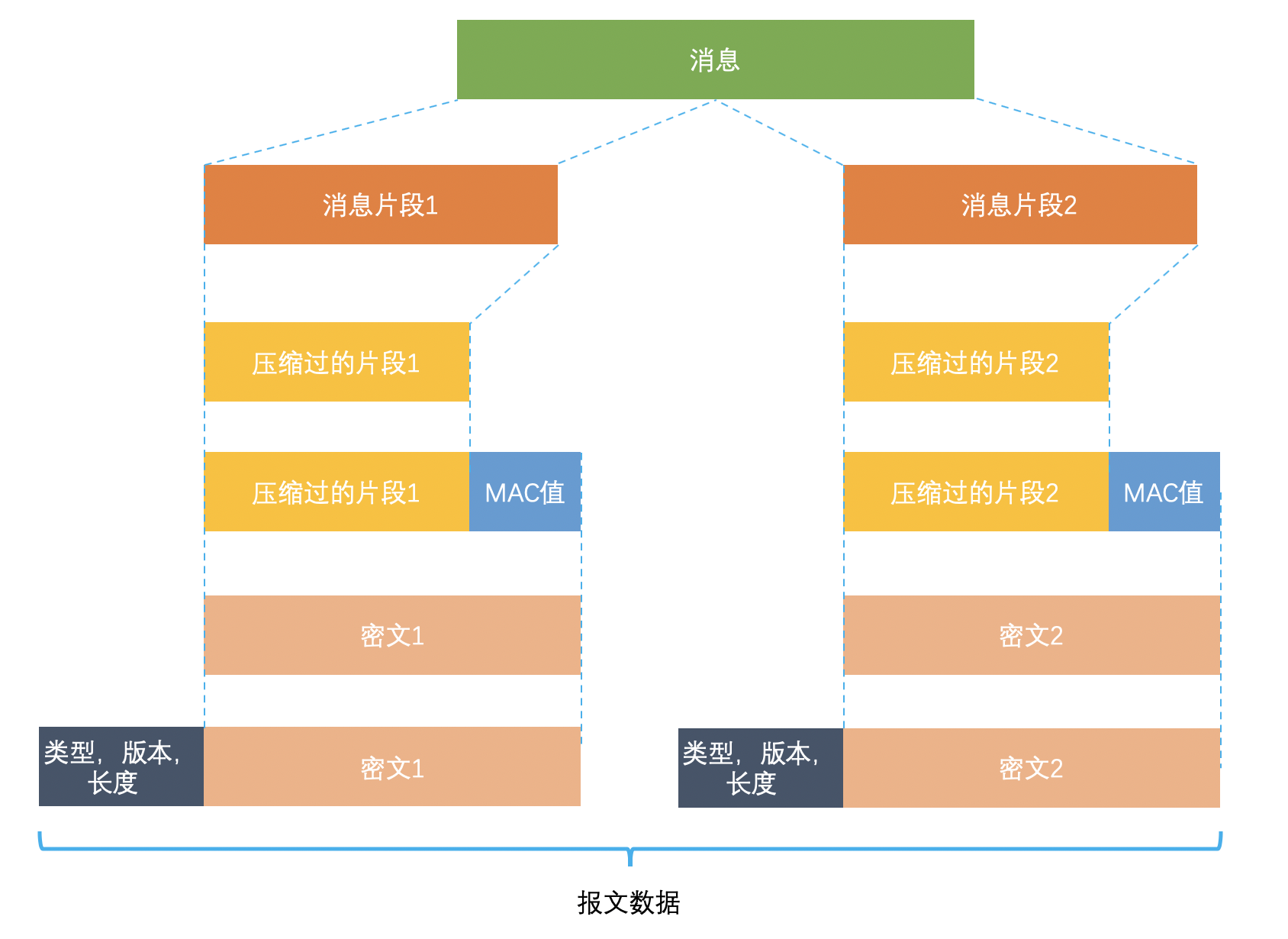
场景-HTTPS一定安全可靠吗?
场景描述1
客户端通过浏览器发请求的时候,被假基站转发到一个中间人服务器,和中间人服务器完成了TLS握手,然后中间人服务器和目标服务器完成了真正的TLS握手。具体步骤如下:
“假基站”
是指一个恶意的设备或系统,它伪装成合法的移动通信基站,与移动设备建立连接,以便拦截、监听或干扰通信流量。假基站可以用来进行中间人攻击,即在通信双方之间插入自己,以便监视或篡改通信。
- 客户端向服务端发送HTTPS请求时,被假基站转发到了一个中间站服务器,接着,中间站服务器向这个请求所指明的服务端发送HTTPS请求。此时,客户端与中间人服务器进行TLS握手,中间人服务器与真正的服务器进行TLS握手。
- 客户端和中间服务器进行握手过程中,中间服务器发送自己的公钥证书给客户端(这不就露馅了??),客户端验证证书真伪,拿到证书公钥,生成随机数后拿公钥加密,发送给中间服务器。中间服务器用私钥解密得到随机数。随后两者开启对称加密通信。
- 中间服务器和服务端进行握手过程中,也是上述类似操作,随后进入对称加密通信阶段。
- 在后续的通信过程中,中间服务器使用对称加密密钥A解密客户端发来的请求,然后通过B加密信息转发给服务器,随后B解密服务器传回的信息,A加密信息返回给客户端。
从客户端角度看,它是看收不到有个中间服务器给转发请求的响应的。也就说这个中间服务器可以偷看信息交互内容!!
但是这种场景的发生是有前提的
- 客户单点击接受了中间人服务器证书。换句话说,确实露馅,客户端在验证服务端证书的时候当然能确定这个中间服务器是非法的,浏览器会给提示的。但是同意的话,那没跑了。(讲真好几年前真的见过很多次这种情况,大多数都被我同意了,因为是查作业题……害怕)
- 电脑病毒,被恶意注入了不安全的根证书
如何避免?
以上两点做好防护
HTTPS双向认证,服务端也需认证客户端身份

所以HTTPS一定安全可靠吗?
通过分析上述这个问题,问题所达到的前提其实是和HTTPS无关的。
HTTPS协议本身目前为止是没有漏洞的……
场景描述2
既然如此,为啥抓包能抓到HTTPS数据?
对于HTTPS来说,中间人能够看到明文数据,需要满足以下两点:
- 服务端不会校验客户端身份√
- 客户端信任服务端——服务端必须有对应域名的私钥?
想要拿到私钥,有以下三种方式
- 去网站服务端拿到私钥
- 去CA证书拿域名签发私钥
- 自己签发证书,需要浏览器信任
抓包其实使用的就是第三种方式,客户端首先需要安装一个Fiddler证书,这里起的就是认证作用。
HTTP/1.1=>HTTP/2=>HTTP/3的演变
| 比较 | 1.1 | 2 | 3 |
|---|---|---|---|
| 改进 | 持久化 管道化 |
头部压缩 二进制格式 并行传输,解决队头阻塞 双方都可建立流(客奇服偶) |
解决TCP队头阻塞 直接改用UDP↑ 更快建立连接 连接迁移 |
| 缺陷 | 响应头无法压缩延迟大 多次相同首部浪费多 没有优先级控制 服务器被动响应 响应队头阻塞 |
TCP层的队头拥塞(丢包) |
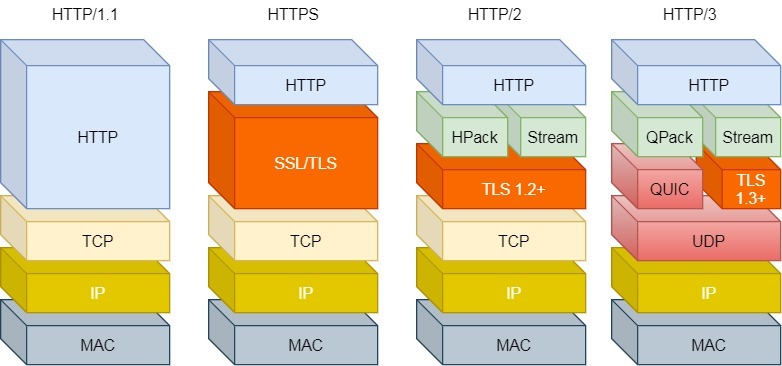
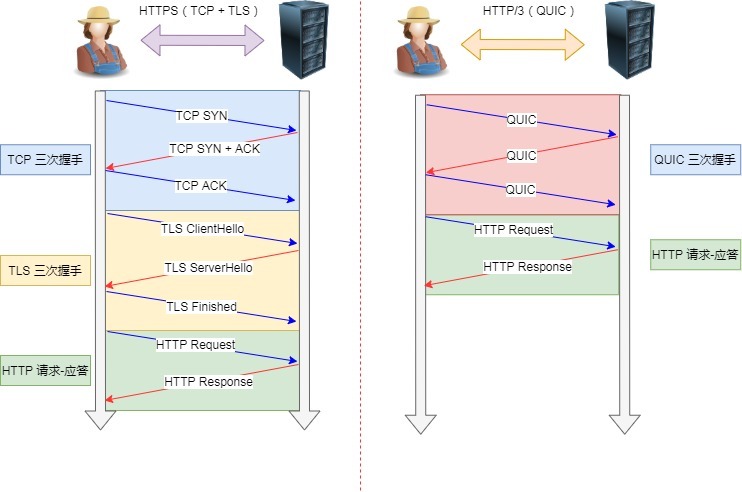
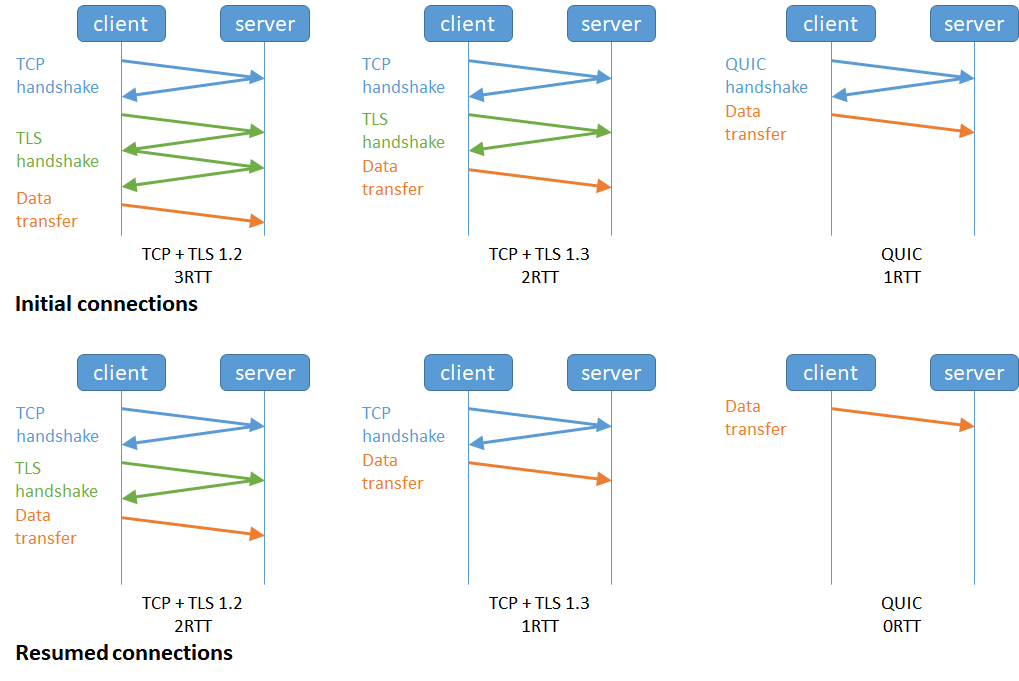
QUIC协议怎么看着这么常用!
那么当移动设备的网络从 4G 切换到 WIFI 时,意味着 IP 地址变化了,那么就必须要断开连接,然后重新建立连接。而建立连接的过程包含 TCP 三次握手和 TLS 四次握手的时延,以及 TCP 慢启动的减速过程,给用户的感觉就是网络突然卡顿了一下,因此连接的迁移成本是很高的。
而 QUIC 协议没有用四元组的方式来“绑定”连接,而是通过连接 ID 来标记通信的两个端点,客户端和服务器可以各自选择一组 ID 来标记自己,因此即使移动设备的网络变化后,导致 IP 地址变化了,只要仍保有上下文信息(比如连接 ID、TLS 密钥等),就可以“无缝”地复用原连接,消除重连的成本,没有丝毫卡顿感,达到了连接迁移的功能。
介绍一下WebSocket
首先再次介绍一下TCP协议,TCP协议是全双工,但是HTTP/1.1却只允许半双工。为啥?
因为HTTP协议设计之初就是为了客户端请求服务器数据获得网页展示和响应,没有考虑到网页游戏这种需要大量互动的情景。所以一种新的应用层协议WebSocket被设计出来。
怎么建立Websocket连接?
TCP三次握手后,先用HTTP协议进行一次通信
如果想用Websocket,那么在HTTP请求中带上特殊请求头
1
2
3
4
5header: {
Connection: Upgrade 升级协议
Upgrade: WebSocket WebSocket协议
Sec-WebSocket-Key: T2a6wZlAwhgQNqruZ2YUyg==\r\n 随机生成的base64代码
}【一次握手】如果对端支持WebSocket,那么开始WebSocket握手,并且根据随机码用某种公开的算法生成另一段字符串,放在Set-WebSocket-Accept头中,带上101协议切换状态码,返回给浏览器
【两次握手】浏览器也用这种公开算法去将那个随机码转化成一段字符串,对比一致则通过验证
然后就可以使用Websocket格式通信了
WebSocket 是基于HTTP的新协议 ××××!!!!
介绍一下RPC
RPC协议出现的比HTTP协议早,没有TCP粘包问题。
TCP
1 | graph LR |
✅基本认识
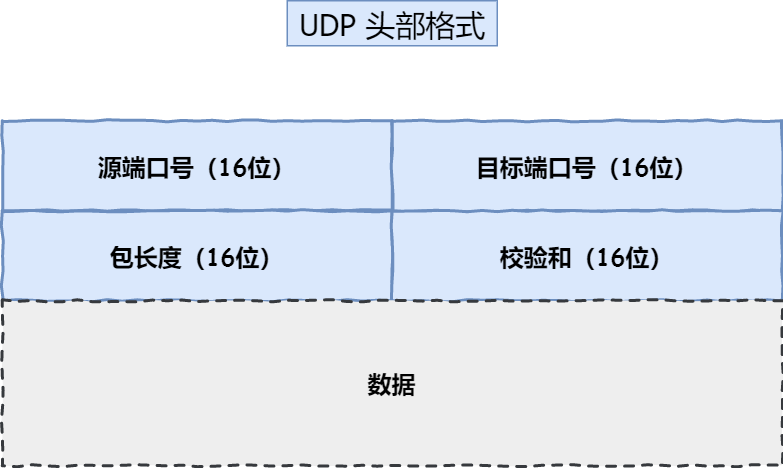
TCP头部格式
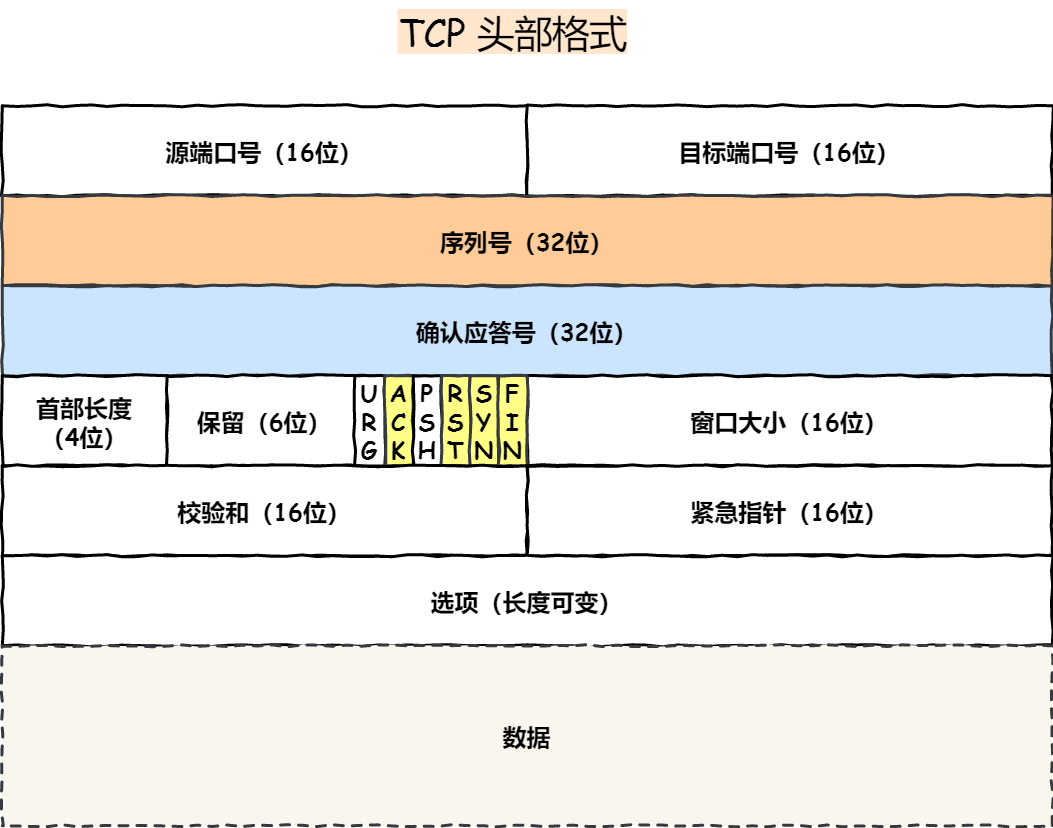
确定一个TCP连接:源地址、源端口、目的地址、目的端口
最大TCP连接数=客户端IP数+客户端端口数
✅TCP和UDP的区别
两者都是传输层协议。
- UDP不提供复杂的控制机制,利用IP提供面向无连接的通信服务。TCP是面向连接的,传输前需要先建立连接。
- UDP一对一或者一对多或者多对多服务。TCP一对一两点服务。
- UDP尽最大努力交付,不保证可靠交付数据(QUIC解决)。TCP是可靠交付数据,无差错不丢失不重复按序到达。
- UDP没有拥塞控制,发送速率很快。TCP有拥塞控制和流量控制,能保证数据安全性。
- UDP首部固定且小,8字节。TCP首部长,开销大。
- UDP包发送,有边界,可能会丢包乱序。TCP流发送,没有边界。
- UDP的分片是分的IP层MTU,在IP层分片重组然后在给传输层。TCP分的是传输层MMS,在传输层分层组装。
场景
- UDP经常用于包数量小的一些如DNS、SNMP、视频通话、多媒体等
- TCP经常用于FTP文件传输、HTTP/THHPS传输等
✅TCP和UDP可以使用同一个端口吗?
可以。
传输层端口号的作用是区分同一个主机上不同应用程序的数据包。
在数据链路层中,通过 MAC 地址来寻找局域网中的主机。在网际层中,通过 IP 地址来寻找网络中互连的主机或路由器。在传输层中,需要通过端口进行寻址,来识别同一计算机中同时通信的不同应用程序。
两者在内核中时两完全相互独立的软件模块。在主机收到数据包时,可以在IP头的协议号字段中得知数据包时TCP还是UDP,从而分送处理。随后根据给的端口号送到对应程序处理。
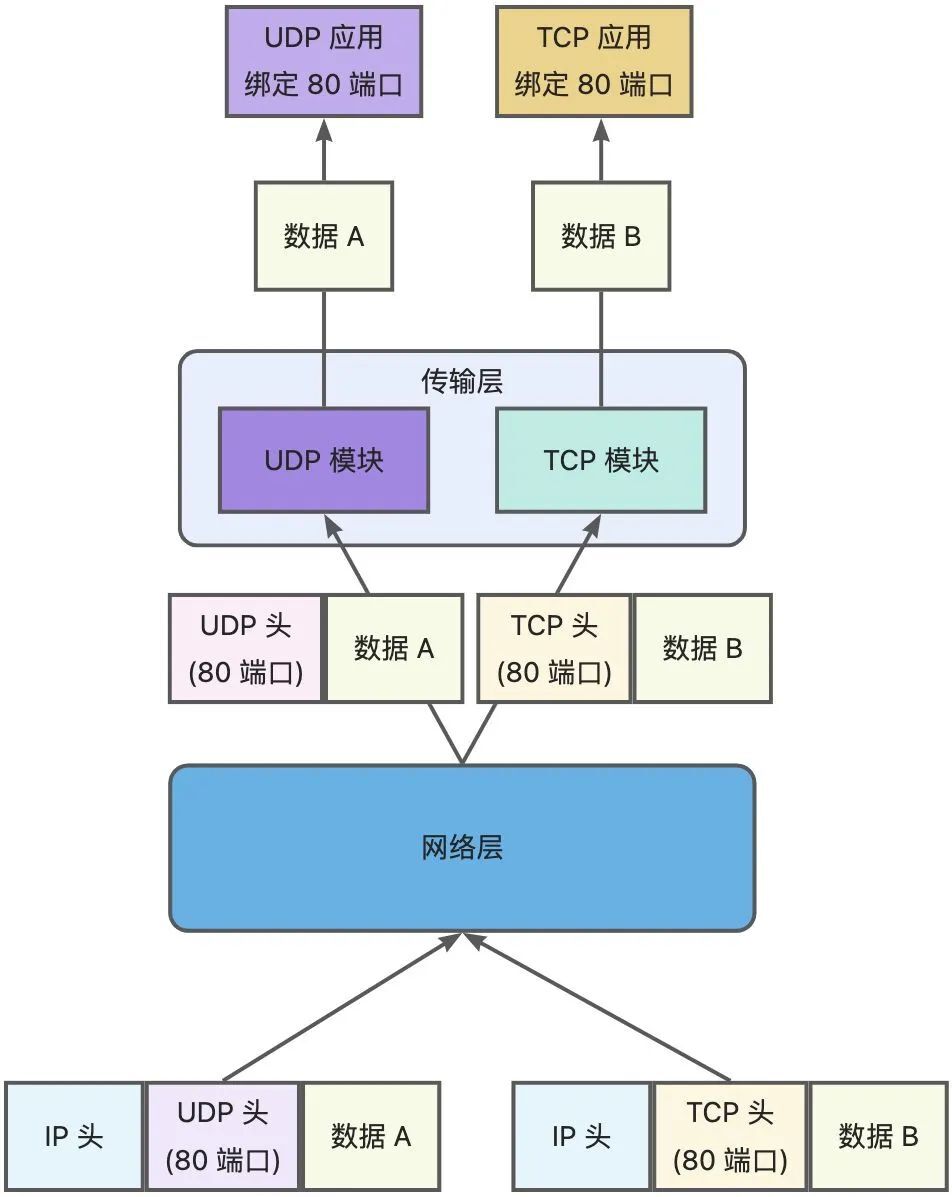
✅多个TCP服务进程可以绑定同一个端口吗?
同时绑定一个地址的情况下绑定同一个端口肯定是不行的(Address already in use);
绑定的地址不同的情况下绑定同一个端口是可行的。
——两个TCP同时绑定IP和端口号都相同,执行bind()时会出错↑
当然还有一个特殊情况:绑定0.0.0.0这个地址意味着绑定了主机上所有的IP地址。
✅客户端的端口可以重复使用吗?
可以,只要保证源IP地址、目的IP地址、源端口、目的端口有一不一致(TCP连接不同)就好。
✅如何解决服务端重启时,报错“Address already in use”的问题?
当我们重启 TCP 服务进程的时候,意味着通过服务器端发起了关闭连接操作,于是就会经过四次挥手,而对于主动关闭方,会在 TIME_WAIT 这个状态里停留一段时间,这个时间大约为 2MSL。
当 TCP 服务进程重启时,服务端会出现 TIME_WAIT 状态的连接,TIME_WAIT 状态的连接使用的 IP+PORT 仍然被认为是一个有效的 IP+PORT 组合,相同机器上不能够在该 IP+PORT 组合上进行绑定,那么执行 bind() 函数的时候,就会返回了 Address already in use 的错误。
要解决这个问题,我们可以对 socket 设置 SO_REUSEADDR 属性。
这样即使存在一个和绑定 IP+PORT 一样的 TIME_WAIT 状态的连接,依然可以正常绑定成功,因此可以正常重启成功。
✅客户端 TCP 连接 TIME_WAIT 状态过多,会导致端口资源耗尽而无法建立新的连接吗?
要看客户端是否都是与同一个服务器(目标地址和目标端口一样)建立连接。
如果客户端都是与同一个服务器(目标地址和目标端口一样)建立连接,那么如果客户端 TIME_WAIT 状态的连接过多,当端口资源被耗尽,就无法与这个服务器再建立连接了。即使在这种状态下,还是可以与其他服务器建立连接的,只要客户端连接的服务器不是同一个,那么端口是重复使用的。
✅如何解决客户端 TCP 连接 TIME_WAIT 过多,导致无法与同一个服务器建立连接的问题?
打开 net.ipv4.tcp_tw_reuse 这个内核参数。
因为开启了这个内核参数后,客户端调用 connect 函数时,如果选择到的端口,已经被相同四元组的连接占用的时候,就会判断该连接是否处于 TIME_WAIT 状态。
如果该连接处于 TIME_WAIT 状态并且 TIME_WAIT 状态持续的时间超过了 1 秒,那么就会重用这个连接,然后就可以正常使用该端口了。
🈯连接🈯断开
🈯拥塞处理
✅TCP怎么保证可靠性?
- 序列号和确认:TCP 中的每个数据段都有一个唯一的序列号,以便接收方可以按正确的顺序重组数据。接收方会发送确认消息(ACK)来告知发送方已经成功接收到数据。如果发送方在合理的时间内没有收到确认,它会重传相应的数据段。
- 数据重传:如果发送方没有收到接收方的确认消息,或者接收方检测到丢失的数据,TCP 会自动重传丢失的数据段,以确保数据的完整性和可靠性。
- 流量控制:TCP 使用窗口机制来控制数据的流量,以防止发送方发送过多的数据,导致接收方无法处理。接收方可以通过调整窗口大小来告知发送方其可接受的数据量。
- 拥塞控制:TCP 使用拥塞控制算法来防止网络拥塞。如果网络中发生拥塞,TCP 会减少发送速率以减轻网络压力,然后逐渐增加发送速率以测试网络是否已恢复正常。
- 延迟确认:TCP 允许接收方延迟发送确认消息,以减少网络上的确认消息数量,从而提高效率。但是,发送方通常会采用超时重传机制,以确保数据及时被接收确认。
- 有限状态机:TCP 在通信的不同阶段使用有限状态机来管理连接的建立、维护和关闭。这有助于确保连接的稳定性和可靠性。
✅https 建立连接的过程中,为什么用非对称加密来交换密钥?
主要目的是确保通信的机密性和安全性。
- 一把公钥一把私钥,公钥可传递,私钥自己攥着,很安全
- CA认证,数字签名,是否真实
- 使用非对称加密交换会话密钥
✅如果有第三方传给客服端一个假密钥呢,如何判定?
CA认证+自主判断…
🈯怎么通过数字证书验证服务端身份的呢?
✅为什么 https 建立连接用非对称加密,传输数据用对称加密呢?
前者是为了确认信息传输的两方是否是对的,后者是确认好人之后能够高效的加密解密数据。
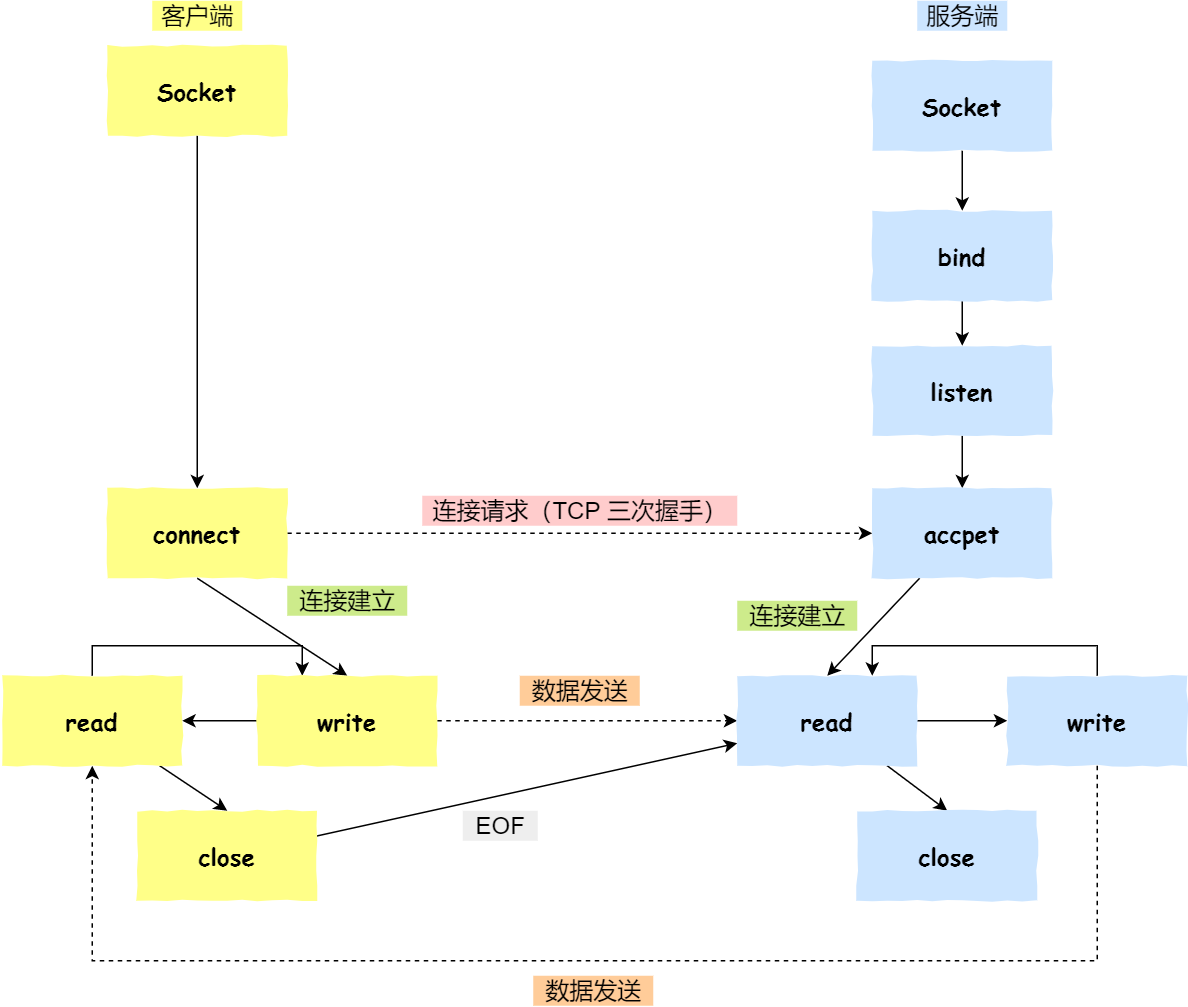
💦Socket编程
IP
✅DNS解析过程(应用层-两种方式)
✅交换机(链路层)自学习过程
交换机自学习(Switch Self-Learning)是指网络交换机通过监视和学习数据包的源MAC地址来构建MAC地址表,以便正确地转发数据包到适当的目标端口。以下是交换机自学习的过程:
初始状态:当交换机首次启动或重置时,其MAC地址表为空。交换机不知道任何设备的位置或MAC地址。
数据包到达:当数据包到达交换机的某个端口时,交换机会检查数据包中的源MAC地址。
学习源MAC地址:交换机将源MAC地址与接收到数据包的端口关联起来,并将这个信息添加到其MAC地址表中。如果交换机已经知道这个MAC地址,它会更新该地址的条目。
广播数据包:如果交换机无法在其MAC地址表中找到目标MAC地址(即目标MAC地址不在MAC地址表中),它将数据包广播到所有其他端口,以便找到目标设备。这是因为交换机不知道目标设备的确切位置,所以它需要广播以确定目标设备在哪个端口上。
学习目标MAC地址:当目标设备响应广播并将响应数据包发送回交换机时,交换机会学习到目标设备的MAC地址,并将其与接收到数据包的端口关联起来,然后将其添加到MAC地址表中。
更新MAC地址表:交换机会持续监视流经它的数据包,不断学习和更新MAC地址表。这使得交换机能够在以后的数据包中直接将数据包转发到正确的端口,而无需广播。
通过这个自学习的过程,交换机能够有效地管理和优化数据流,减少网络中的广播风暴,并提高网络性能。它通过构建和维护MAC地址表来确定每个设备的位置,从而在数据包转发时能够更精确地选择目标端口。这有助于减少网络拥塞,提高数据包传输效率。
✅服务端如何知道多个请求属于哪个用户?
- 会话管理:
- 会话是一种服务器用来跟踪用户在网站上的活动的方式。每个用户在访问网站时都会获得一个唯一的会话标识,通常以会话cookie的形式存储在用户的浏览器中。服务器可以使用这个会话标识来识别用户并将多个请求关联到同一个用户。
- 会话管理可以在服务器端实现,通常会使用服务器端的存储(如内存、数据库或缓存)来存储会话数据。一旦用户成功登录,服务器会为用户创建一个会话,并将会话标识发送到用户的浏览器。随后的每个请求都会包含这个会话标识,服务器通过它来确定请求属于哪个用户。
- 身份验证:
- 用户登录是识别用户的另一种常见方式。当用户进行登录操作时,服务器会验证其凭据(通常是用户名和密码),并在成功验证后将用户标识与会话相关联。
- 身份验证可以基于不同的机制,包括基本身份验证、令牌验证、OAuth 2.0、OpenID Connect 等。一旦用户登录,服务器就可以在后续请求中使用用户的身份信息来确定请求属于哪个用户。
- IP 地址和其他标识符:
- 服务器还可以根据用户的 IP 地址和其他浏览器提供的标识符来尝试识别用户。然而,这种方法通常不够可靠,因为多个用户可能共享相同的 IP 地址,而且一些用户可能使用代理服务器或 VPN,导致 IP 地址变化频繁。
🈯服务器状态码
⚙️OS
进程
概念
当我们在运行一个可执行文件的时候,这个文件会被装载到内存中,接着CPU会执行这个程序中的每一条指令,这个运行中的程序被称为进程。
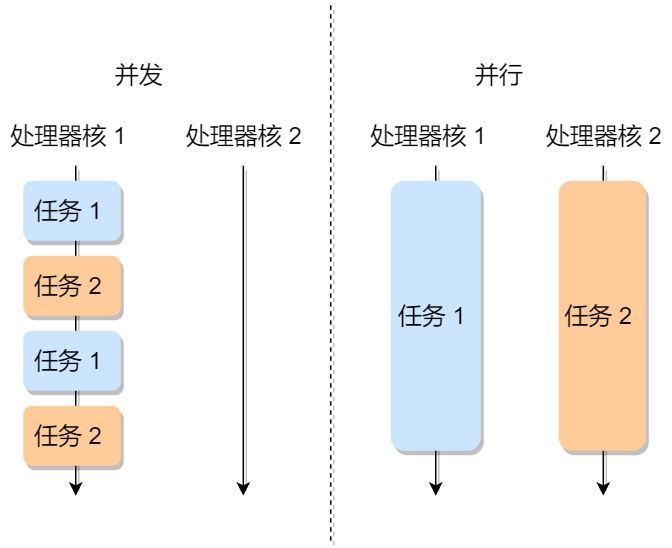
状态
- 运行
- 就绪
- 阻塞
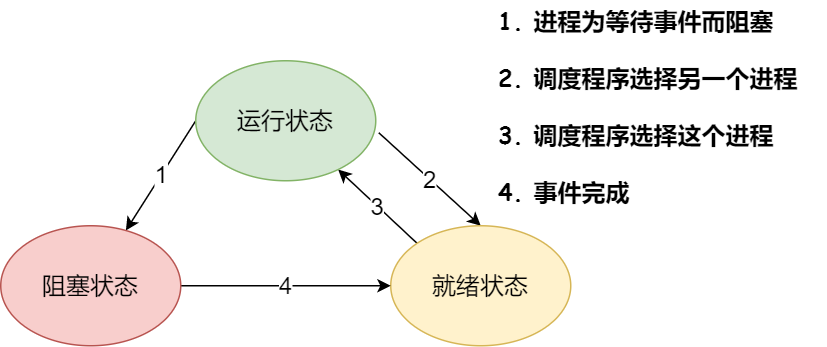
- 创建
- 结束
- 阻塞
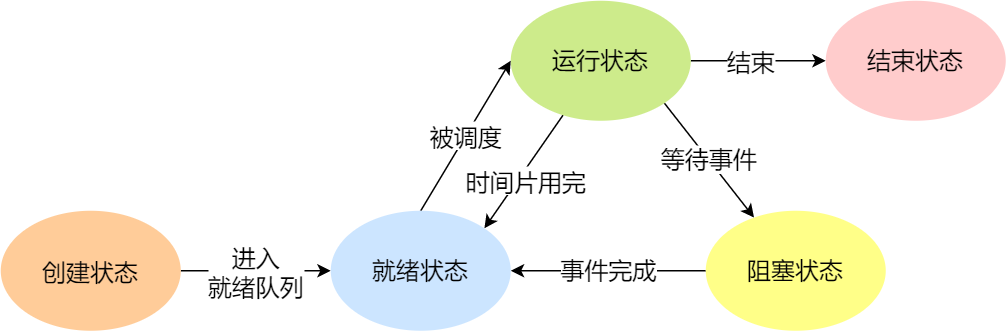
- 挂起
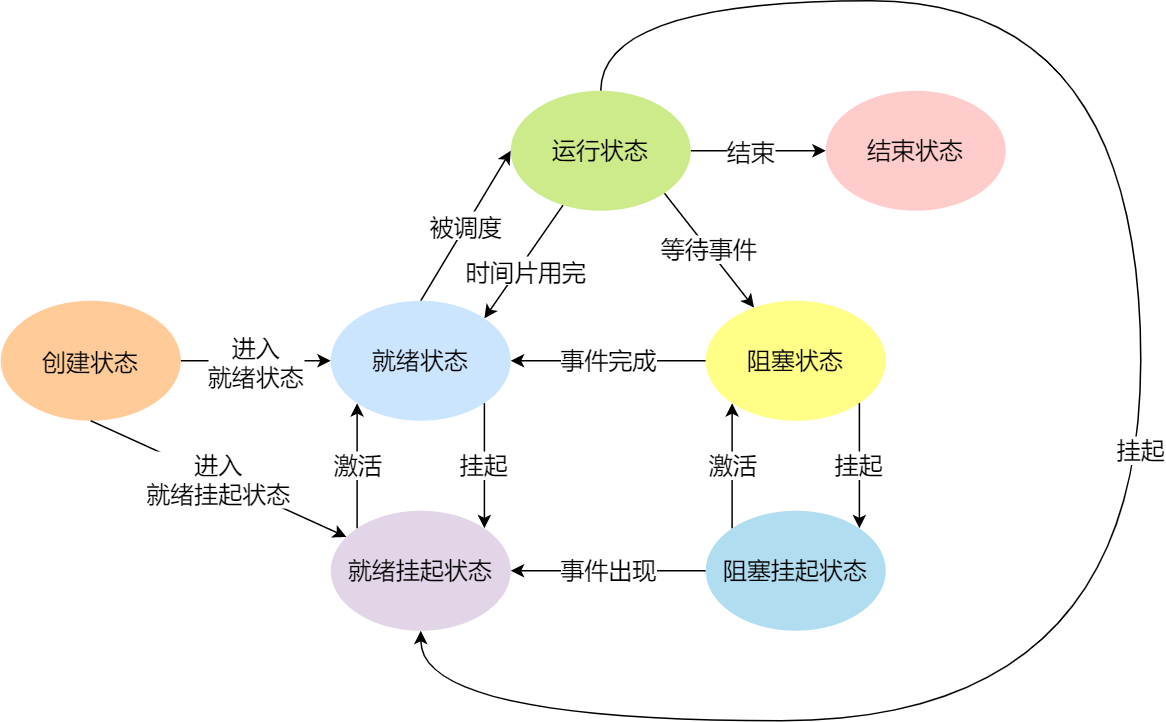
进程的控制结构
在OS中,使用**进程控制块PCB(process control clock)**数据结构来描述进程。
- PCB是进程存在的唯一标识
- PCB包含的信息
- 进程描述信息:进程标识符、用户标识符
- 进程控制和管理信息:状态、优先级
- 资源分配清单:内存/虚拟地址空间信息、文件列表和I/O设备信息
- CPU相关信息:CPU状态信息等
- 每个PCB如何组织
- 链接:将相同状态的进程链在一起,组成各种队列,有运行指针
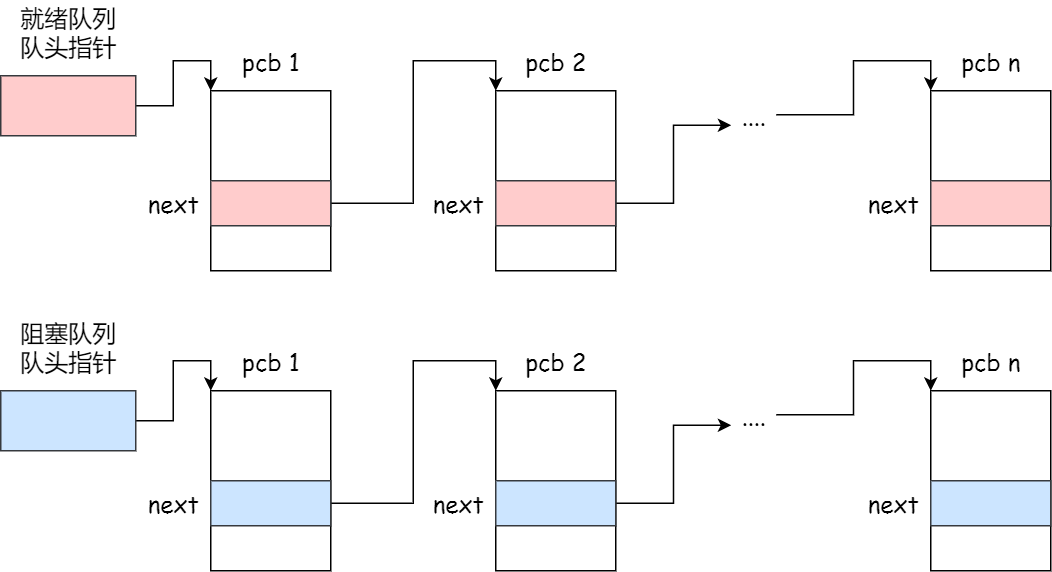
- 索引:将相同的状态的进程组织在一个索引表中,索引表每项指向响应的PCB
- 一般会选择链接方式,因为临时进程的创建和销毁频繁,更适合这种灵活插入删除的结构!
- 链接:将相同状态的进程链在一起,组成各种队列,有运行指针
进程的控制
创建—终止—阻塞—唤醒的过程。
- 创建:OS允许在一个进程中创建另一个进程,并允许子进程继承父进程的所有资源。过程↓
- 申请一个空白的PCB,向PCB中填写一些控制管理进程的信息(唯一标识)
- 分配运行时所必需的资源
- 将PCB插入到就绪队列,等待被调度运行
- 终止:正/异常结束、外界干预导致进程终止。子进程被终止的时候将资源还给父进程;父进程终止后子进程变成孤儿进程,会被1号进程收养,并由1号进程对它完成状态收集工作。过程↓
- 查找需要终止的进程的PCB
- 如果处于执行状态,立即终止,将CPU分配给其他进程
- 如果还有子进程,将其交给1号进程接管
- 将该进程所有的资源归还给OS
- 将其从PCB所在的队列中删除
- 阻塞:当进程需要等待某一事件完成时,可以调用阻塞语句将自己阻塞等待,一旦被阻塞等待,就只能由另一个进程唤醒。过程↓
- 找到即将被阻塞进程标识号对应的PCB
- 如果为运行状态,保护现场,转换状态,停止运行
- 将PCB移到阻塞队列里
- 唤醒:正在阻塞队列中的进程所期待的事件出现,才能被唤醒。过程↓
- 找到这个PCB
- 将这个PCB从阻塞队列移出
- 想这个PCB放进就绪队列里
进程的上下文切换
一个进程切换到另一个进程。
CPU上下文切换
大多数OS支持多任务,即大于CPU数量的任务同时运行。但实际上并非同时运行。
OS需要事先帮CPU设置好CPU寄存器和程序计数器。寄存器这个东西是一个内部容量小但是速度极快的缓存。计数器是用来存储CPU正在执行的指令位置、或者即将执行的下一条指令的位置。
CPU寄存器和计数器是CPU在运行任何任务之前,所必须依赖的环境。这些环境就叫做CPU上下文。
CPU上下文切换就是把前一个任务的上下文保存起来(系统内核),然后加载好新的上下文,最后根据计数器所指的新任务进行跳转运行。
↑当之前那个任务再次被分配给 CPU 运行时,CPU 会根据内核中保存的信息重新加载这些上下文,这样就能保证任务原来的状态不受影响,让任务看起来还是连续运行。
进程上下文切换
进程上下文切换不仅包括虚拟内存、栈、全局变量等用户空间资源,还包括内核堆栈、寄存器等内核空间的资源。
通常将交换信息保存在进程的PCB中,当要运行这个进程的时候,需要从PCB中取出上下文,将其恢复到CPU中,运行。
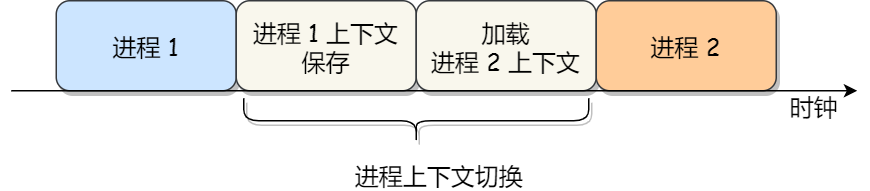
进程上下文切换的开销非常关键,应该把更多的时间花费在执行程序上,而不是切换。
发生进程上下文切换的场景
- 公平调度,CPU时间切片,轮流分配
- 进程在系统资源不足,需要更多资源,挂起,执行别的先
- 进程sleep函数主动挂起
- 优先级更高的来了
- 发生硬件中断
线程
thread
为什么使用线程什么是线程
线程是一种实体,它满足
- 实体之间可以并发运行
- 实体之间共享相同的地址空间
线程是进程当中一条执行流程。每个线程都有各自一套独立的寄存器和栈,这样可以确保现成的控制流是相对独立的。
线程的优缺点
优点
- 一个进程中可以同时有多条线程
- 各个线程之间可以并发执行
- 各个线程之间可以共享地址空间和文件等资源
缺点
- 当进程中一条线程崩溃时,会导致所属进程所有线程崩溃
两者的比较↓↓
线程的上下文切换
现成是调度的基本单位,所谓“OS的任务调度”,实际上调度的对象就是线程,而进程只是给线程提供了虚拟内存和全局变量等资源。
- 若两线程属于同一个进程,切换过程和切换进程上下文一样
- 若两线程不属于同一进程,虚拟内存保持不动,切换线程的私有数据、寄存器等不共享的数据即可
线程的实现
线程实现方式分三种
- 用户线程User:在用户空间内实现的线程,由用户态的线程库来完成的线程管理
- 内核线程Kernel:内核中实现的线程,是内核管理的线程
- 轻量级进程LightWeight:在内核中用来支持用户线程
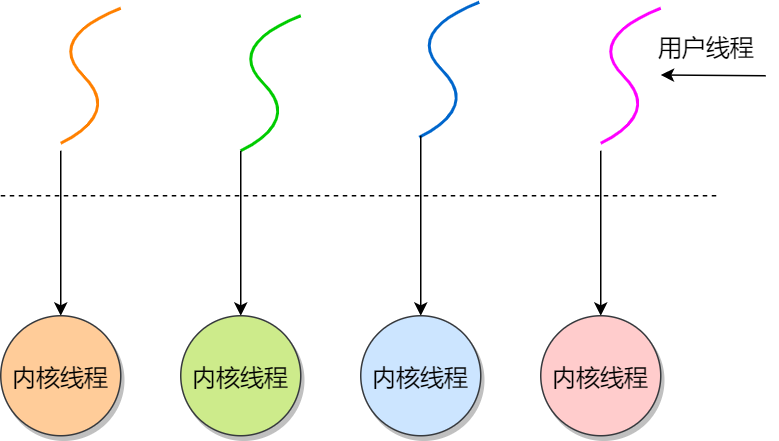
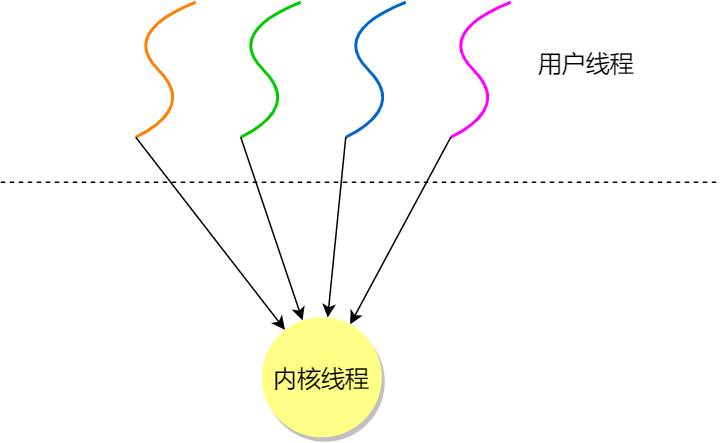
用户线程和内核线程的对应关系:
一对一、多对一、多对多
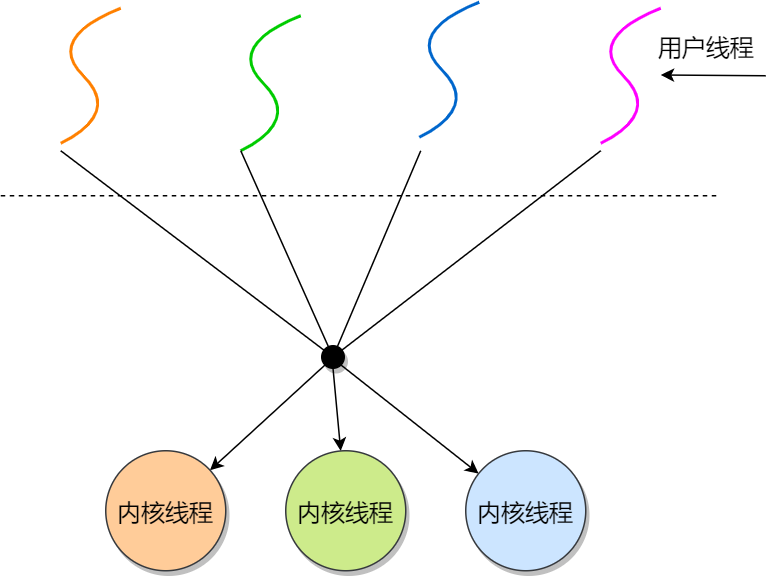
用户线程的理解和优缺点
理解:
用户线程是基于用户态的线程管理库实现的。线程控制块TCB也是在库里实现的,对于OS而言是看不到TCB的。
所以用户线程整个线程的管理调度OS不直接参与,而是通过用户级线程库来实现。包括创建、终止、同步和调度。
用户级线程模型(多对一):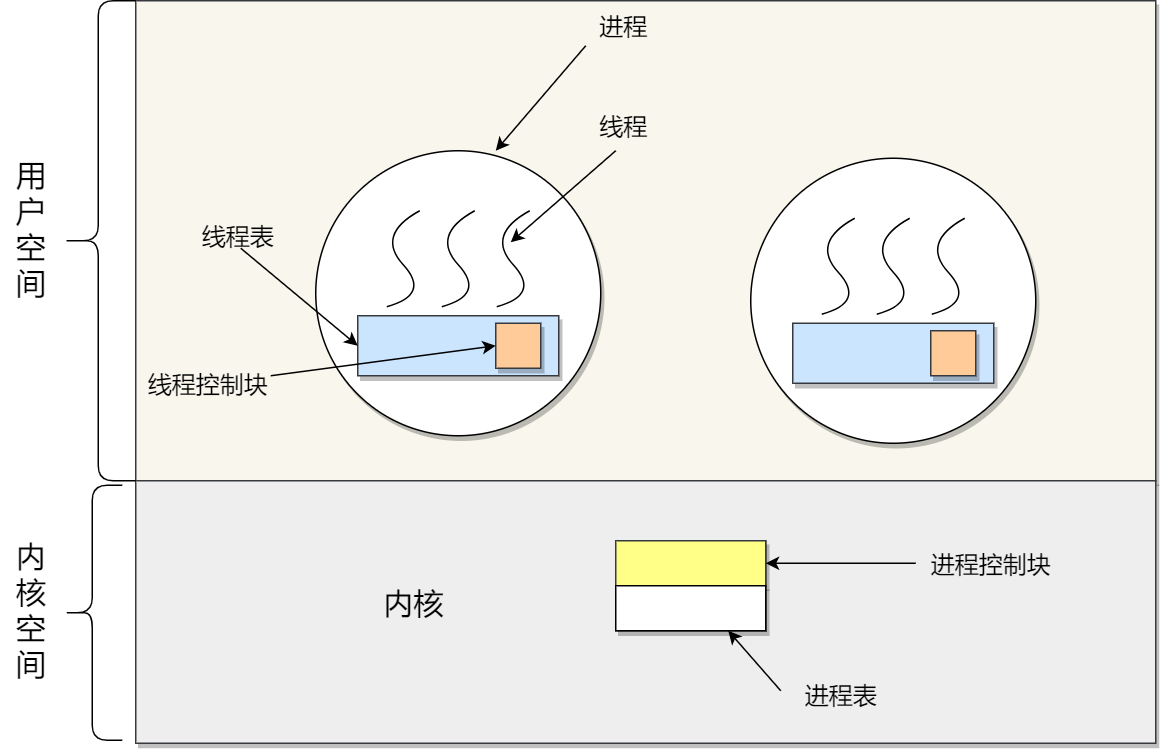
优点:
- TCB由用户级线程管理库函数来维护,可用于不支持线程技术的OS
- 用户线程切换也是↑,无需用户态和内核态切换,速度很快
缺点:
- OS不参与线程调度,某用户线程发起系统调用一阻塞,所有用户线程都无法执行
- CPU使用权用户态线程是无权打断别的县城然后使用的,只用OS才有,但用户线程不受OS管理
- 时间片分配给了进程,那么多线程执行的时候每个线程得到的时间片就少了
内核线程的理解和优缺点
理解:
内核是由OS管理的,TCB放OS里。
内核线程模型(一对一):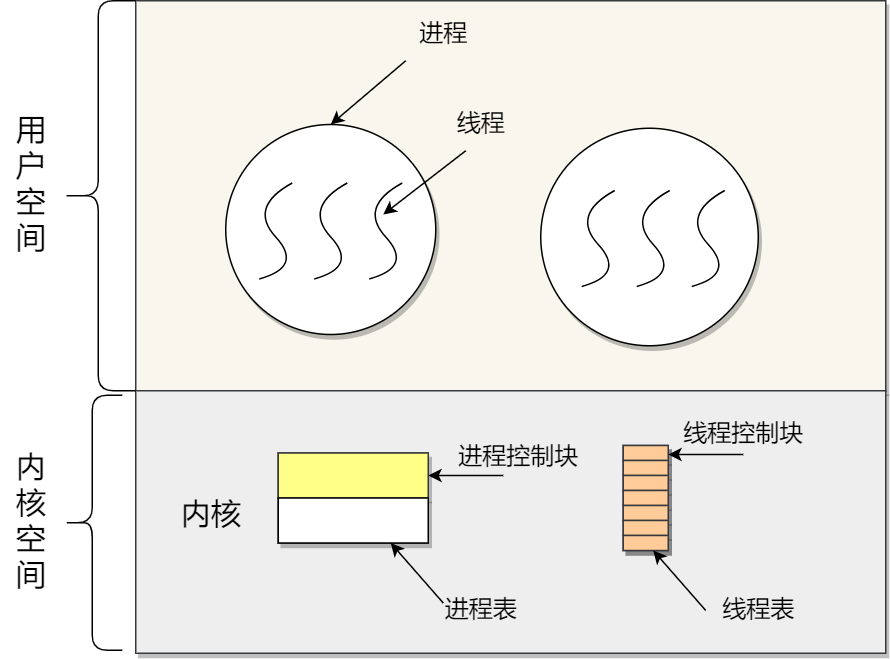
优点:
- 一个进程中,某内核线程发起的系统调用被阻塞,不会影响其他内核线程的运行。
- 分配给线程,多线程的进程获得更多的CPU运行时间
缺点:
- 支持内核线程的OS中,由内核来维护进程和线程的上下文信息
- 线程的状态变化都由OS把控,开销点大
轻量级进程的理解和优缺点
理解:
Light-weight process,LWP 是内核支持的用户线程,一个进程可以有一个或多个LWP,每个LWP是跟内核线程一对一映射的,且LWP由内核管理并和普通进程一样被调度。
在大多数系统中,LWP与普通进程的区别也在于它只有一个最小的执行上下文和调度程序所需的统计信息。
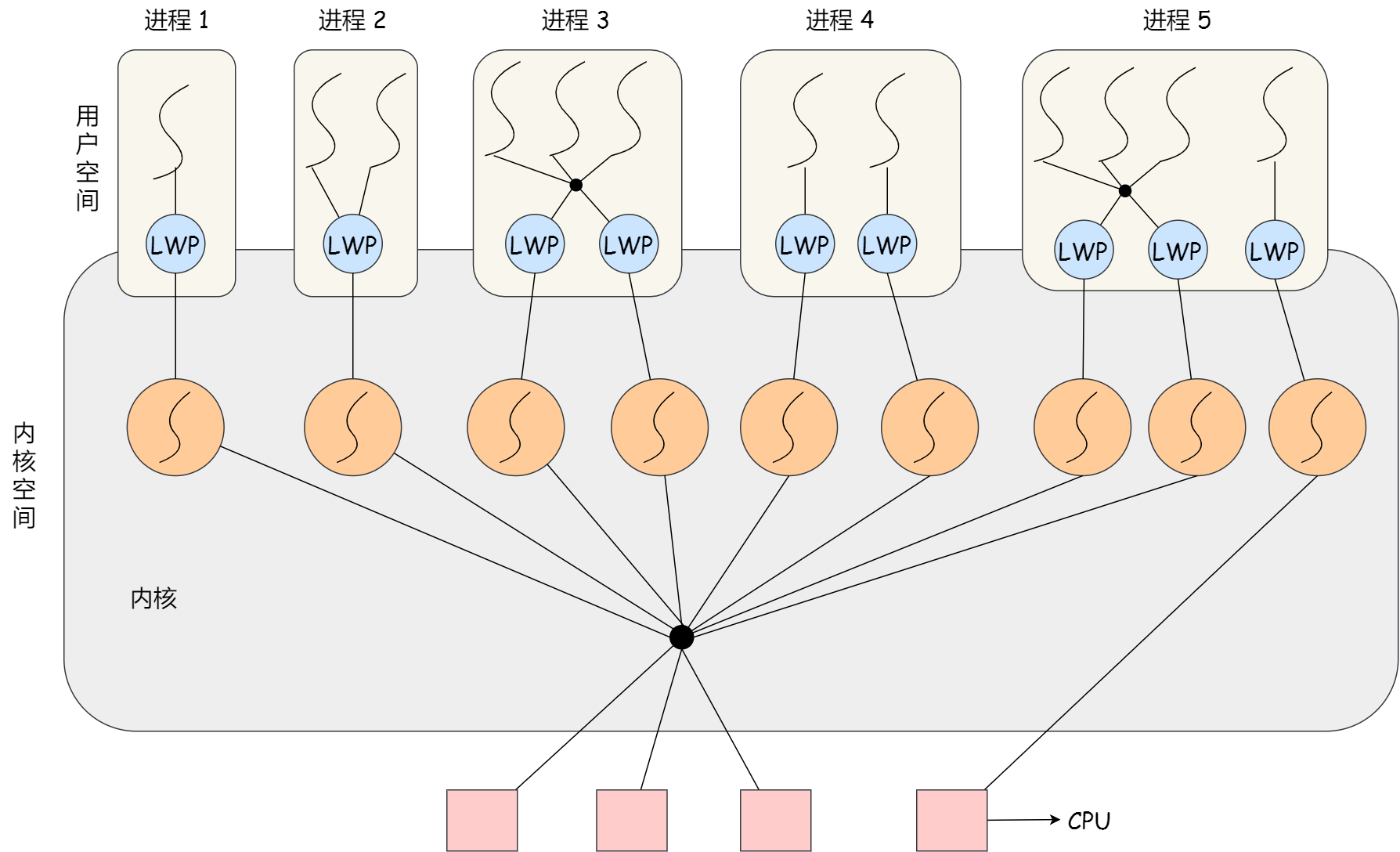
(1:1 / N:1 / M:N / 组合)模式
优点/缺点?
调度
选择一个进程运行这一功能是在操作系统中完成的,通常称为调度程序(scheduler)
✅调度时机
在进程生命周期中,当进程行一个运行状态到另外一个状态的时候,其实会触发一次调度。
✅调度原则
- 当触发I/O请求,等待时CPU是空闲的,调度程序需要从就绪队列中选择一个进程来执行。
- 要提高系统的吞吐率,调度程序要权衡长任务和短任务进程的进行时间和运行完成的数量。
- 周转时间越小越好,等待时间不宜过长(周转时间=运行时间+等待时间)。
- 就绪队列中进程的等待时间不宜过长。
- 交互式较强的应用,响应时间最好短一些。
✅基于上述五条原则,我们需要
- ↑CPU利用率:让CPU忙起来
- ~吞吐量:控制吞吐量合适
- ↓周转时间:越短越好
- ↓等待时间:越短越好
- ↓响应时间:越短越好
调度算法
- 先来先服务first come first serve
- 最短作业优先shortest job first-运行时长
- 高响应比优先highest response ratio next-$优先权=(等待时间+要求服务时间)/要求服务时间$,些许理想难实现
- 时间片轮转round robin-哐叮哐叮哐叮,长短要合适20ms-50ms
- 最高优先级highest priority first-(静态优先级,动态优先级)(抢占式,非抢占式)
- 多级反馈队列multilevel feedback queue-RR+HPF,多个队列,优先级从高到低,时间片从短到长
✅进程和线程的区别
进程(Process)是资源拥有的基本单位;线程(Thread)是调度的基本单位。
一些重要的区别:
定义:
- 进程:进程是操作系统分配资源的基本单位,它包括一个独立的内存空间、一个或多个线程以及与其他进程隔离的系统资源(如文件句柄、网络连接等)。
- 线程:线程是进程内的执行单元,一个进程可以包含多个线程,它们共享相同的内存空间和系统资源。
资源分配:
- 进程:进程之间相互独立,每个进程有自己的内存空间和系统资源,进程之间的通信通常需要使用特定的机制(如进程间通信,IPC)。
- 线程:线程共享相同的进程内存和资源,线程之间的通信更加容易,因为它们可以直接访问相同的内存空间。
开销:
- 进程:创建和销毁进程通常比较耗费资源,因为需要分配和释放独立的内存空间以及管理进程的状态。
- 线程:创建和销毁线程通常比较轻量,因为它们共享相同的资源,只需分配和释放少量内存来存储线程的上下文。
并发性和多核利用:
- 进程:不同进程之间可以在多核处理器上并行执行,但进程间的通信成本较高。
- 线程:线程可以更有效地利用多核处理器,因为它们共享相同的地址空间,可以更容易地实现并发执行。
稳定性:
- 进程:由于进程之间的隔离性,一个进程的崩溃通常不会影响其他进程。
- 线程:一个线程的错误可能会影响同一进程内的其他线程,因为它们共享相同的内存空间。
适用场景:
- 进程:适用于需要高度隔离的任务,如运行不同的应用程序,每个应用程序都作为一个独立的进程运行。
- 线程:适用于需要轻量级并发的任务,如图形界面应用程序、服务器应用程序和多线程编程。
综上所述,进程和线程都有其自身的优点和适用场景。选择使用哪种方式取决于任务的性质和要求。在某些情况下,也可以同时使用进程和线程来充分利用计算资源。
进程之间的通信方式
每个进程的用户空间都是独立的,一般不能相互访问;内核空间共享,所有进程之间的通信必须通过内核。
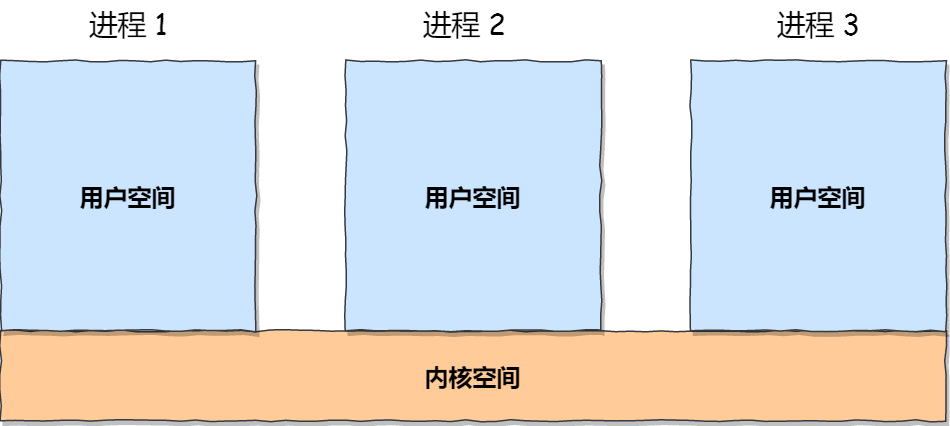
- 管道:效率较低,不适合频繁交换数据
- 前者输出是后者输入
- 管道传输数据是单向的
- 匿名管道、命名管道
- 消息队列:不适合放较大数据,存在用户态和内核态之间的数据拷贝开销
- 保存在内核中的消息链表
- 共享内存:速度提升,无需拷贝
- 不同进程拿出一块虚拟地址映射到相同的物理内存空间
- 信号量
- 一个整数计数器,主要用于实现进程间的互斥和同步,而不是缓存进程之间的通信数据
- 为了防止多进程竞争共享资源,而造成的数据错乱
- PV操作 (P -1若减后<0,说明已被占用,需要阻塞等待; V +1若加后<=0,说明有阻塞,唤起该进程)
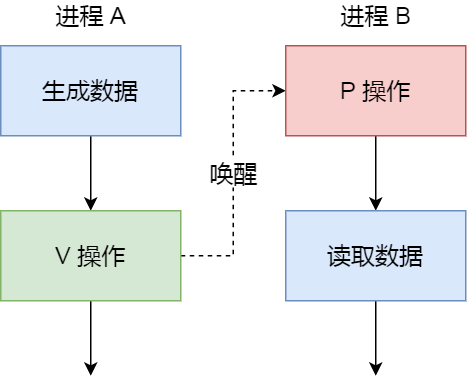
- 信号:对于异常情况下的工作模式,就需要用「信号」的方式来通知进程。
- Socket:前面提到的管道、消息队列、共享内存、信号量和信号都是在同一台主机上进行进程间通信,那要想跨网络与不同主机上的进程之间通信,就需要 Socket 通信了。
✅如何解决多线程冲突
对于共享资源,如果没有上锁,那么在多线程的环境里,容易发生冲突。
多线程相互竞争操作共享变量时,结果有不确定性。由于多线程执行操作共享变量的这段代码可能会导致竞争状态,称这段代码为临界区。它是访问贡献资源的片段,一定不能给多线程同时执行。
互斥和同步
互斥:保证一个线程在临界区执行,其他线程应该被阻止进入临界区。
同步:并发进程/线程在一些关键点上需要相互等待和通信,这种制约等待和交互信息称为同步。
实现:
- 加锁解锁
- 信号量PV操作
生产者消费者

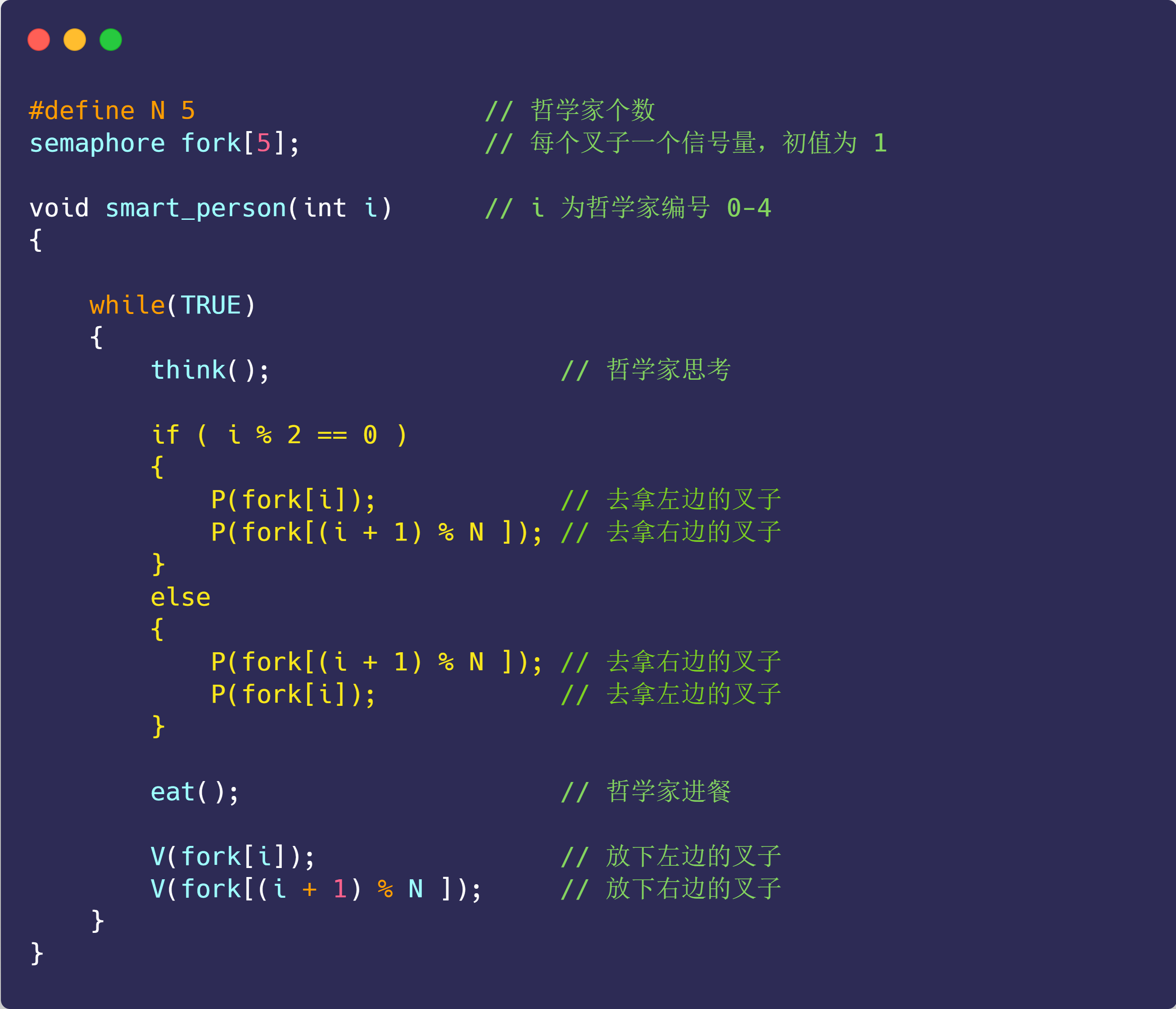
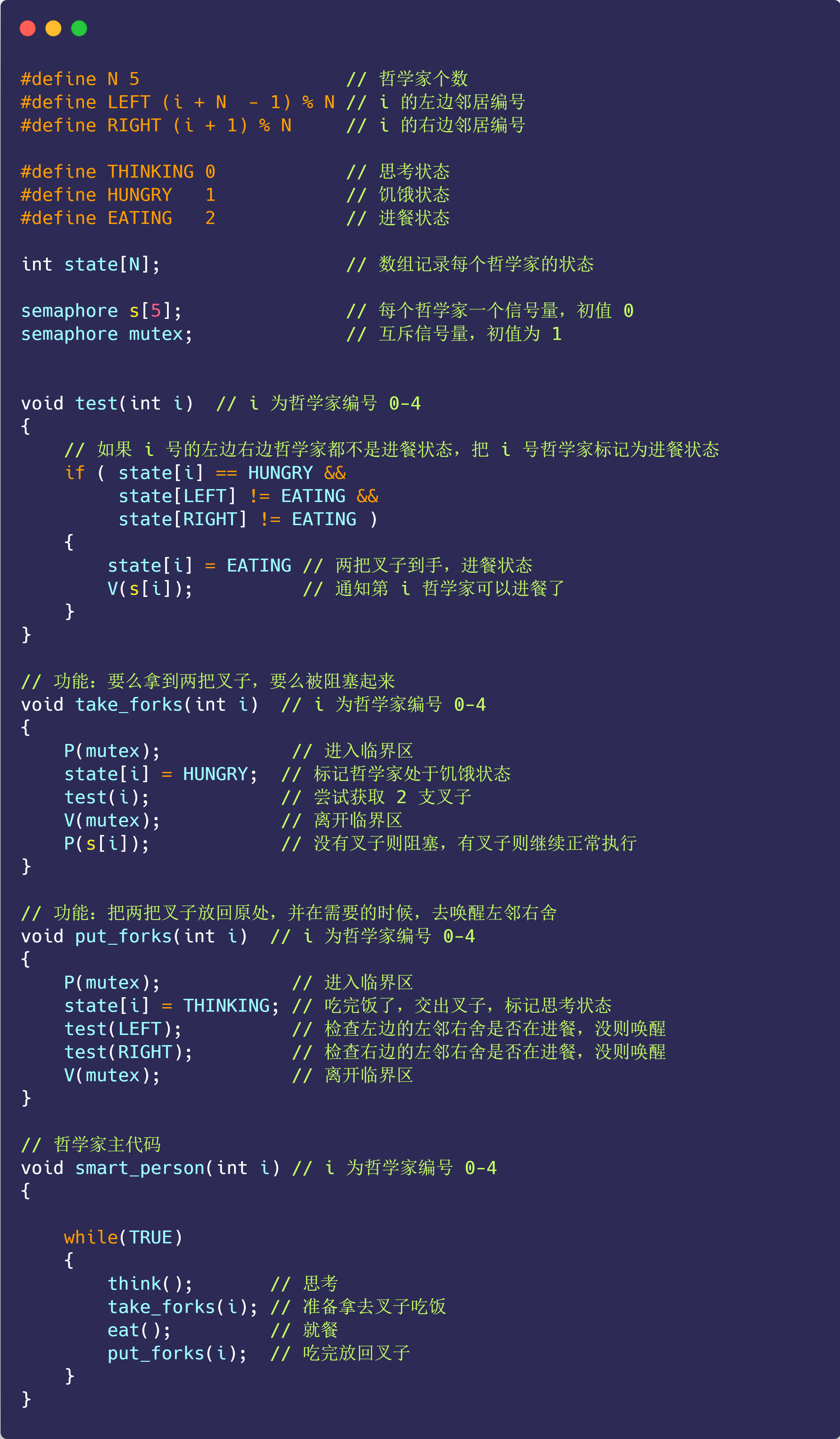
哲学家就餐


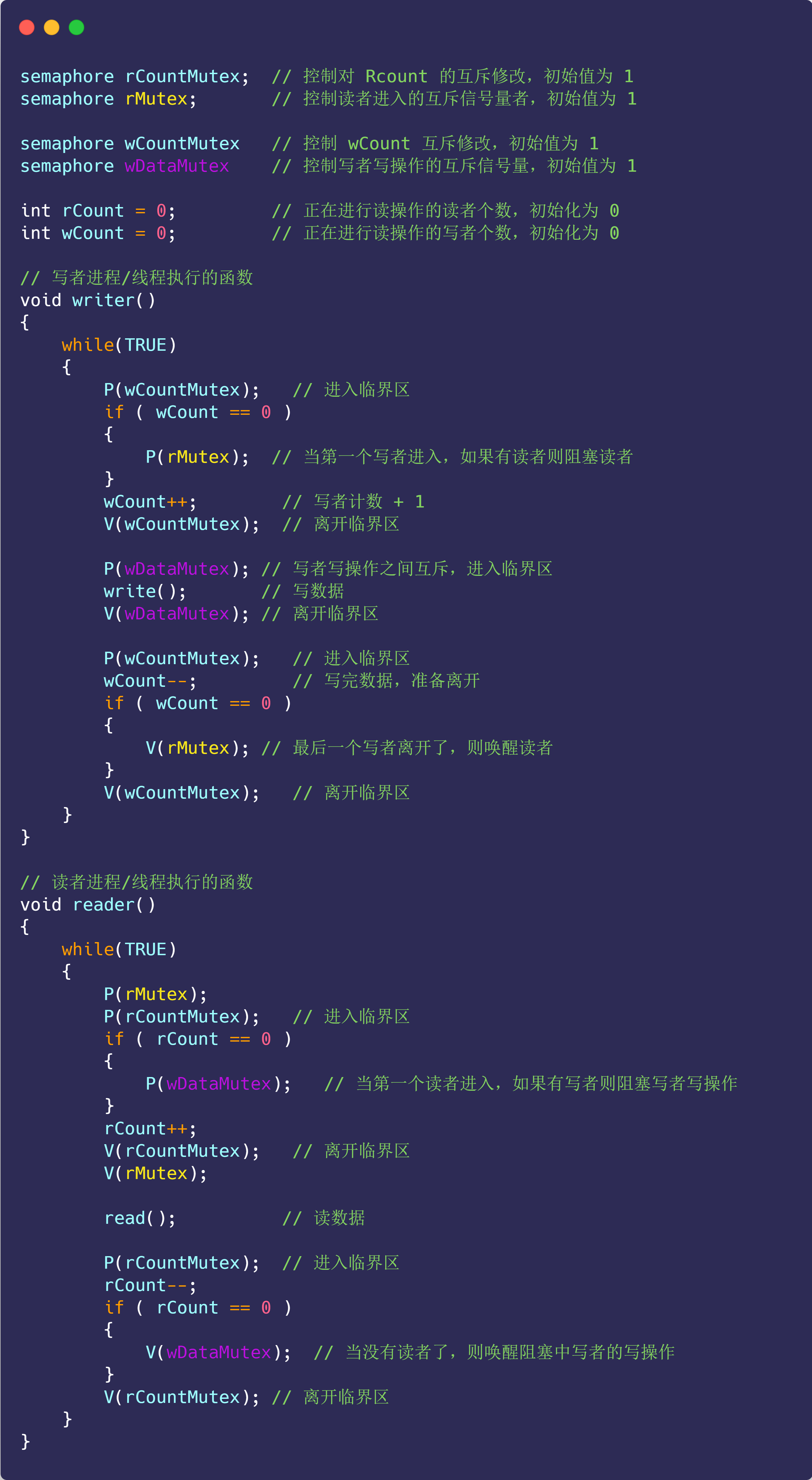
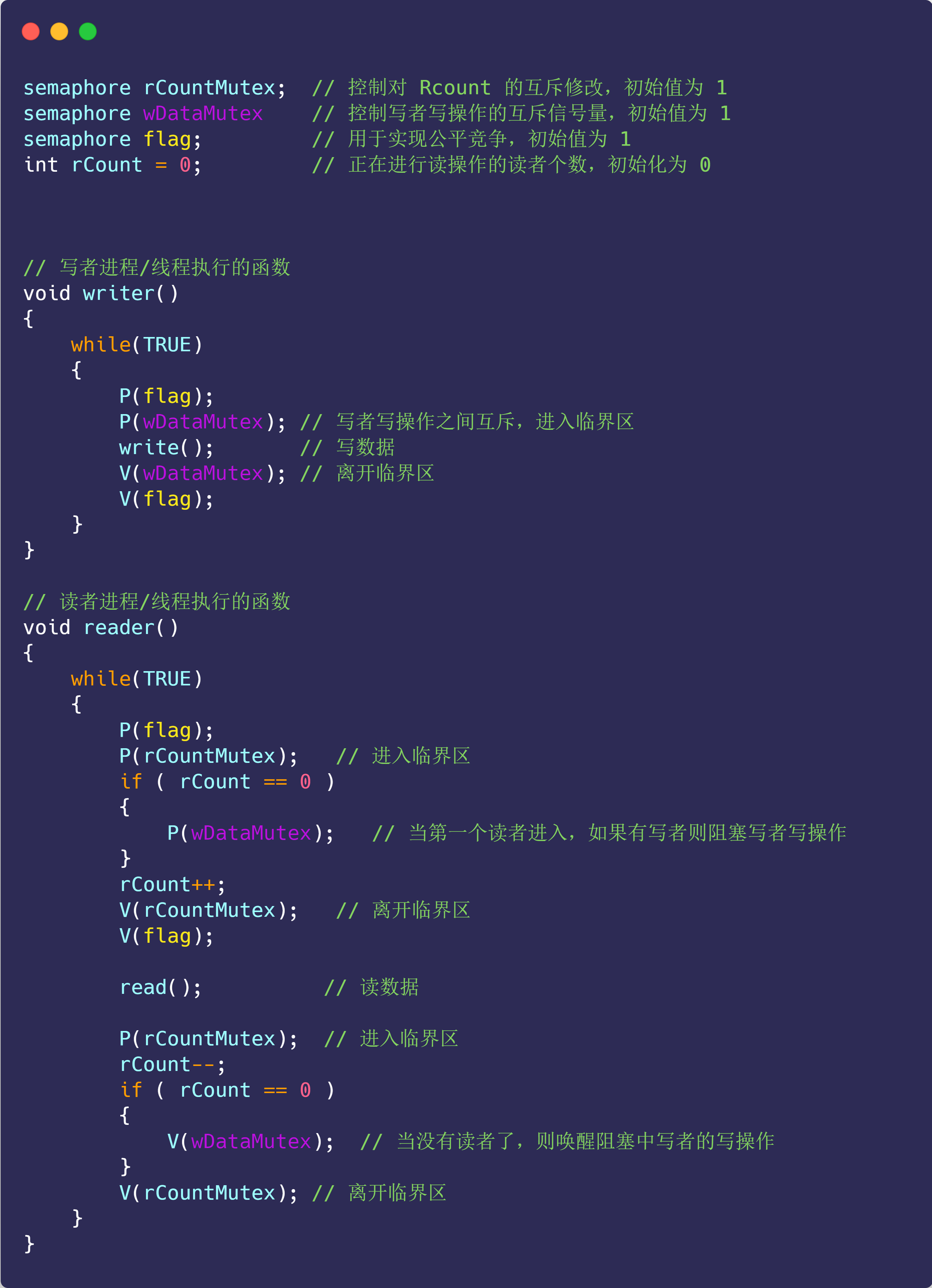
读者写者

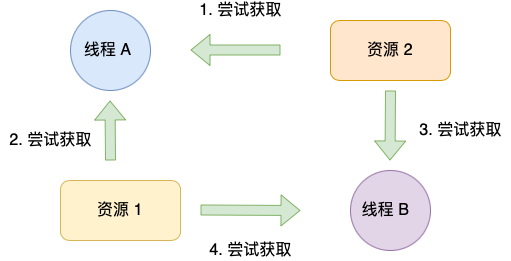
✅怎么避免死锁
死锁概念
两个线程为了保护两个不同的资源使用了两个互斥锁,两个锁应用不当时,可能会造成两个线程都在等待对方解锁,从而形成死锁的局面。
条件缺一不可成死锁
- 互斥条件:多个线程不能同时使用同一个资源
- 持有并等待条件:线程A在等待资源2的同时并不会释放自己已持有的资源1
- 不可剥夺条件:资源在自己使用完之前不能被其他线程获取
- 环路等待条件:两个线程获取资源的顺序构成了环形链
死锁成因↑
利用工具排查死锁
jstack
避免死锁的办法
资源有序分配
线程 A 和 线程 B 获取资源的顺序要一样,当线程 A 是先尝试获取资源 A,然后尝试获取资源 B 的时候,线程 B 同样也是先尝试获取资源 A,然后尝试获取资源 B。也就是说,线程 A 和 线程 B 总是以相同的顺序申请自己想要的资源。
我们使用资源有序分配法的方式来修改前面发生死锁的代码,我们可以不改动线程 A 的代码。
我们先要清楚线程 A 获取资源的顺序,它是先获取互斥锁 A,然后获取互斥锁 B。
所以我们只需将线程 B 改成以相同顺序的获取资源,就可以打破死锁了。
悲观锁乐观锁等各种锁
✅一个进程可以创建多少个线程
因素:
- 进程的虚拟内存空间上限
- 系统参数限制
线程崩溃进程也会崩溃吗
实在是不打算了解了呃呃
🎨HTML/CSS
✅HTML5相对于其他版本的优势
- 增加了很多语义化标签,比如header main article section footer nav aside等
- 增加媒体标签,使更好替代flash,比如audio vedio
- 更加侧重语义化,对SEO搜索引擎优化很友好
- 针对JS增加了很多可操作的接口和全局属性
- 可移植性增强,多端适配
- 其他:canvasJS绘图、webWorkers、WebSockets、RAF、离线存储
✅HTML5优势细说
标签分类
布局标签状态标签列表标签文本标签……
新增表单功能
| 属性名 | 功能 |
|---|---|
| placeholder | 提示文字(注意:不是默认值, value 是默认值),适用于文字输入类的表单控件。昂昂! |
| required | 表示该输入项必填, 适用于除按钮外其他表单控件。 |
| autofocus | 自动获取焦点,适用于所有表单控件。果然会用到这个! |
| autocomplete | 自动完成,可以设置为 on 或 off ,适用于文字输入类的表单控件。注意:密码输入框、多行输入框不可用。 |
| pattern | 填写正则表达式,适用于文本输入类表单控件。注意:多行输入不可用,且空的输入框不会验证,往往与 required 配合。 |
音频视频标签
新增全局属性
| 属性名 | 功能 |
|---|---|
| contenteditable | 表示元素是否可被用户编辑,可选值如下:true :可编辑false :不可编辑 |
| draggable | 表示元素可以被拖动,可选值如下:true :可拖动false :不可拖动 |
| hidden | 隐藏元素 |
| spellcheck | 规定是否对元素进行拼写和语法检查,可选值如下:true :检查false :不检查 |
| contextmenu | 规定元素的上下文菜单,在用户鼠标右键点击元素时显示。 |
| ==data-* 这个用过哦!== | ==用于存储页面的私有定制数据。doc.dataset.* 这个和下一个都是H5中非常有用的自定义属性!== |
| ==aria-*== | ==用于增强网页的可访问性,特别是对于使用屏幕阅读器等辅助技术的用户。== |
| lang | 语言 |
| class/id/style/title | 样式、标识、标签等 |
离线存储
H5使用离线存储机制,使得网页应用程序可以在用户离线时仍可正常运行。也就是说用户离线了,也可以利用浏览器中缓存的一些数据进行一些操作,提高用户体验。
实现方式
ApplicationCache应用缓存程序——一个存储机制,允许开发者定义哪些资源应该被缓存,保证离线也能加载。这些资源包括文档、样式、JS、图像等。
实现步骤
创建缓存清单文件CacheManifest:创建一个扩展名为.appcache的文本文件
在HTML中引用缓存清单:
<html manifest:'....appcache'></html>配置缓存策略:
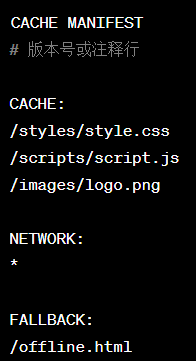 cache需要缓存的network不需要缓存的fallback替代资源
cache需要缓存的network不需要缓存的fallback替代资源设置离线事件处理:
1
2
3
4
5
6window.applicationCache.addEventListener('updateready', function() {
if (window.applicationCache.status === window.applicationCache.UPDATEREADY) {
// 缓存已更新,执行相关操作cached、noupdate、downloading、updateready
window.applicationCache.swapCache();
}
}, false);
浏览器兼容性
- 向后兼容:正常处理旧版
- 旧浏览器理解:使用Shims/Polyfills等包使得实现H5功能
- 渐进增强和优雅降级:前者是开发时先构建基本功能,再逐步增加高级特新;后者是从高级功能开始,逐渐适配较旧的浏览器。
- 特性检测:开发者可以对浏览器进行特性检测,评估浏览器能力,提供对应的代码功能服务。
- 标准化:H5是W3C标准化的,开发者可以比较安心地在不同浏览器上实现相同效果。
- 移动优先:H5设计考虑了移动设备的普及,提供了移动端友好特性,比如书响应式、触摸、移动设备优化等。
- CanvasSVG:灵活绘制复杂图形。
✅SEO搜索引擎优化
好牛的一方面,似乎会有专门的SEO工程师做这一块。

✅前端跨浏览器/多端兼容性/适配问题
多端兼容适配指应用在各种设备(电脑,手机)上能够正常显示和交互。
- 遵循标准
- 使用浏览器兼容性检测工具
- 响应式设计
- 现代框架
- 服务端渲染
- ……
- 持续监控更新
跨浏览器兼容适配指web应用在不同浏览器中能够正常显示盒交互。
- 遵循Web规范标准
- 响应式设计
- 特性检测,分类给服
- CSS前缀后备
- 用可靠的包
- ……
- 多浏览器测试
✅优化页面性能
MDN版:
Web 性能是客观的衡量标准,是用户对加载时间和运行时的直观体验。
Web性能优化请看准关键性能。
🥗使用dns-prefetch
(有预制菜内味儿了)
DNS-prefetch尝试在请求资源前解析域名。可能是后面要加载的文件/用户尝试打开的链接目标。
浏览器从第三方请求资源的时候必须先将该跨源域名解析为IP地址,然后才可发出请求。(DNS解析)
DNS缓存可以帮助减少对此的延迟,而DNS解析可以导致请求增加明显的延迟。
dns-pre的作用即为帮助开发人员掩盖DNS解析的延迟。
1 | <!--使用↓ 每当站点引用跨源资源的时候,都应在head中如此放置--> |
1 | Link: <https://fonts.googleapis.com/>; rel=dns-prefetch |
注意事项:
dns-pre仅对跨源域上DNS的查找有效,因此需要避免指向本站点/域(浏览器看到提示时站点背后的IP已被解析)
考虑将
dns-prefetch与preconnect提示配对。dns-prefetch只执行 DNS 查询,而preconnect则是建立与服务器的连接。这个过程包括 DNS 解析,以及建立 TCP 连接,如果是 HTTPS 网站,就进一步执行 TLS 握手。将这两者结合起来,可以进一步减少跨源请求的感知延迟。(preconnect最好只用在关键连接上)1
2<link rel="preconnect" href="https://fonts.googleapis.com/" crossorigin />
<link rel="dns-prefetch" href="https://fonts.googleapis.com/" />
🥙优化启动性能
(启动速度,直接影响用户体验)
异步化
启动时,在使用异步脚本标签中加入defer(异步)/async(不阻塞加载但阻塞运行)属性,便于解析器高效处理文档
若需要解码资源文件,最好在worker中做此事
处理浏览器支持的数据格式时,使用设备/浏览器内置的解码器更优
所有能并行的数据处理都该并行化
不要强迫Web引擎构建不必要的DOM
一种简单的hack方式:将html代码保留在文档中,包裹在注释内,阻止渲染,需要的时候再渲染
1
2
3
4
5<div id="foo">
<!--
<div> ... 此处放置需要延迟渲染的HTML代码
-->
</div>1
foo.innerHTML = foo.firstChild.nodeValue; // 以此触发渲染
下载时间
缩小体积
GPU占用时间
数据大小
缩小体积
主观因素
过渡动画、进度条,委婉让用户知晓状态的一些功能
🥪CSS动画和JS动画性能
主要分析CSS(transition,animation)和JS(requestAnimationFrame())动画性能的差异。
.一个简单的的方式去创造当前样式与结束状态样式之间的动画
.提供通过一个初始状态属性值集合与最终状态属性值集合创造动画
.提供一种用 JavaScript 代码制作动画的高效方式,在绘制下一帧前由浏览器调用
简单动画完全可以使用CSS,若实在复杂,JS是佳选。
🌮关键渲染路径
这条将HTMLCSSJS转换为屏幕上的像素的过程无疑是优化性能的关键一环(CRF)。
- 异步/延迟加载或消除非关键资源
- 优化请求数量和每个请求文件的体积
- 通过区分关键资源优先级来优化被加载资源的顺序,缩短关键路径长度
🌯懒加载
延迟加载,非关键资源加载的策略。
- 拆分代码,入口/import
- CSS尽量小,尽快送达
- 字体preload
- 非关键图片懒加载, loading=”lazy”
- 事件处理器加载
🍔渲染页面:浏览器工作原理
就是↓
民间版:
请去看URL->渲染过程,根据这一系列的步骤来优化。
- 请求阶段
- 善用缓存
- 使用httpDNS
- 减少重定向
- 静态资源服务器
- 服务器升级带宽
- 数据库优化
- 缓存动态网页
- 高防服务器
- 解析加载阶段
- DNS预解析预解析html预加载linkscript,尽量避免阻塞,缩短阻塞时间(少,早)
- 按需加载
- 合适统一替代
- 缓存
- 并行请求
- SSR
- 渲染阶段
- 少操作DOM
✅CSS3新特性
- 圆角:border-radius
- 渐变:gradient
- 阴影:box-shadow text-shadow
- 透明度:opacity
- 过渡:transition
- 动画:@keyframes: animation
- 多列布局:column-count column-width
- 媒体查询:@media
- 自定义字体:@font-face
- 伪元素伪类:::before ::after :hover
- Flex布局:display: flex
- Grid布局:display: grid
- 过滤:filter
Flex布局
flex-basis flex
Grid布局
rem布局
浮动布局
🈯BFC
Block Formating Context 块级格式化上下文
我对它的理解是它其实是浏览器一个隐藏方法,当满足一定条件的时候就会调用,这个时候我们就可以说BFC开启了。
BFC开启主要解决这些问题:
- margin塌陷
- 元素内元素开启浮动的时候,元素宽高塌陷
- 浮动元素被另一个兄弟元素覆盖
开启BFC的方式有很多:
- 个人认为副作用最小的是
display: flow-root - 浮动定位、绝对定位
- 行内块元素inline-block
- flex/grid/table布局 多列容器
- overflow!=visible
✅CSS选择器优先级&权重
选择器
属性选择器
1 | a[title] |
伪类选择器
1 | :frist-child |
伪元素选择器
好奇妙的
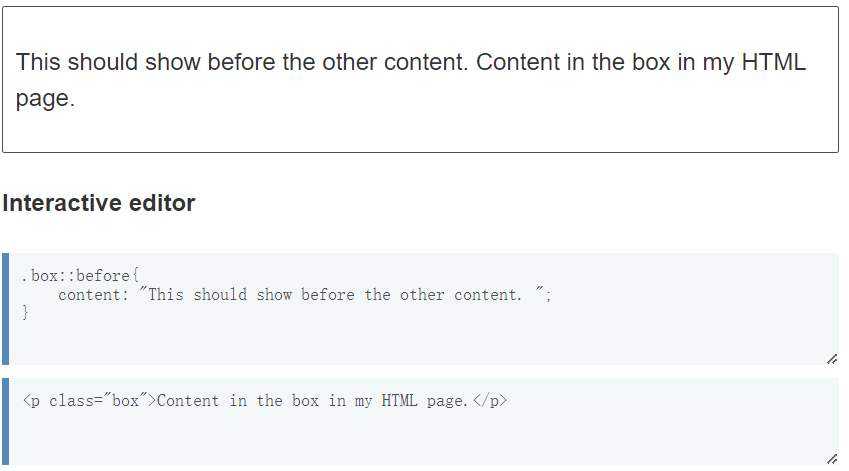
格式化呀↓
1 | artical p::first-line { |
一组特别的伪元素↑
关系选择器
1 | /* 经典的后代选择器-凡是后代 */ |
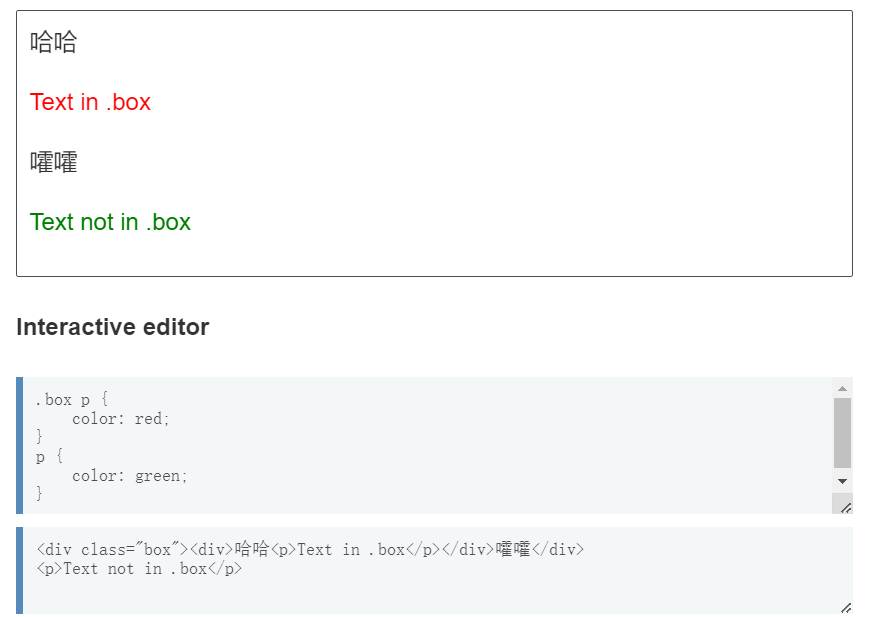
1 | /* 子代关系选择器-直接的子元素 */ |
1 | /* 邻接兄弟选择器-紧随之后的元素 */ |
1 | /* 通用兄弟选择器-都叽吧鸽们! */ |
1 | /* 组合一下 */ |
以上这些特殊的选择器蛮多的,去MDN查吧!会有意外收获的~
选择器权重
- !important
- 内联样式1000:在元素的style中定义
- ID选择器100:通过元素id属性定义
- 类选择器/属性选择器/伪类选择器10:class / [type=1] / :hover
- 元素选择器(类型选择器)/伪元素选择器1:p, div / ::before, ::after
- 全局通用选择器/关系选择器/组合器0:* / img~p
1 | <div id="div1" class="container" style="color: white">啊啊啊啊啊</div> |
1 | #div1 { |
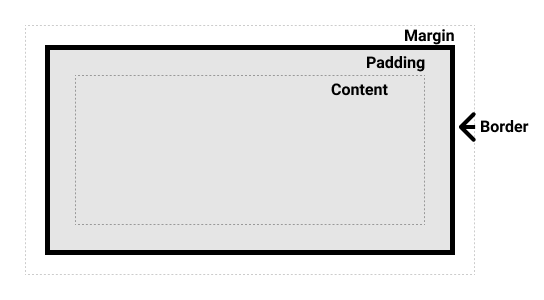
✅盒模型
CSS中所有元素都被一个个盒子包围。广泛使用的两种盒子:块级盒子、内联盒子。两种盒子会在页面流和元素间关系方面表现出不同的行为。
块级盒子
- 盒子会在内联方向上扩展并占据父容器在该方向上的所有可用的空间,大部分情况下和父容器盒子一样宽
- 每个盒子都换行
- width/height属性可以发挥作用
- 内边距、外边距、边框会将其他元素从当前盒子周围推开
内联盒子
- 盒子不会产生换行
- width/height不起作用
- 水平方向内边距、外边距、边框会被应用但不会把其他处于inline状态的盒子推开
- 垂直方向内边距、外边距、边框会被应用且会把处于inline状态的盒子推开
CSS盒模型
模型定义了content padding border margin这些部分
CSS中组成一个块级盒子需要:
- ContentBox
- PaddingBox
- BorderBox
- MarginBox
为了增加一些额外的复杂性,有了两类盒模型,一个是标准盒模型,一个是替代盒模型↓
标准盒模型
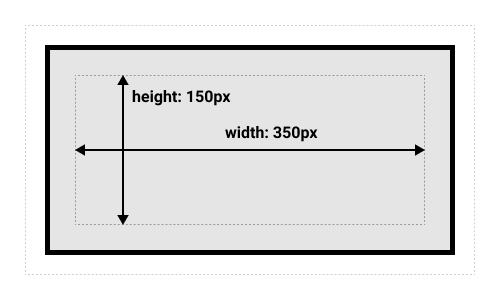
标准盒模型宽高是ContentBox的宽高。
浏览器默认使用这种标准盒模型box-sizing: content-box。
替代(IE)盒模型
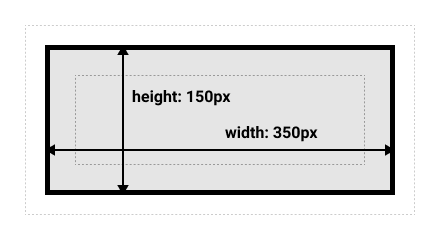
替代盒模型的宽高是ContentBox+PaddingBox+BorderBox的宽高(可见宽高)。
可以通过box-sizing: border-box来实现替代盒模型。
其他常见盒模型
- 内联盒子-display: inline-box
- 内联块级盒子-inline-block
- 弹性盒子-flex
- 网格盒子-grid
- 表格盒子-table table-row table-cell
- 浮动盒子-fload: left/right
- 绝对定位盒子-position: absolute
内联盒子
- 水平方向排列
- 宽度由内容决定,高度由字体大小决定
- 不会自动换行,不会独占一行
- 仅支持水平方向内外边距和边框
内联块级盒子
- 水平方向,一行内,不自动换行
- 但是支持宽高设置和垂直方向边距和边框
✅行内元素和块元素
行内元素-inline
a span em strong img input
- 水平、不独占一行、不自动换行
- 宽高由内容和字体大小决定,也就是说设置宽高无效
- 垂直方向内外边距和边框失效
- 行内元素不能包含块级元素,只能来点小文本/其他行内元素
块级元素-block
hn p div ul/ol/li form
- 独占一行、自动换行
- 宽度默认父元素100%,宽高有效
- 内外边距和边框都有效
- 块级元素内可以包含块级元素、行内元素、文本
背景和边框
z-index在什么情况下生效(=>层叠样式表
position常见属性
实现水平垂直居中
实现元素居中
如何隐藏元素
如何清除浮动样式
css实现透明度的方式
实现Flex两栏布局
实现三列布局
实现流式布局
预处理器和css变量
🦴JS
🈯ES6里面的E和S分别指的是什么?
ES6中E指的是ECMAScript,S指的是Script。
前者是JS的标准化版本,定义了JS的核心语言功能,包括变量、数据类型、操作符、控制结构等。
后者表示的是JS的脚本编程特性,使其适用于在Web浏览器中创建交互式和动态的网页。
🈯JavaScript和ECMAScript区别?
JS是一种基于ECMAScript标准的编程语言,是它的一种实现。它包括了EC定义的核心语言功能,但也包括了其他功能和API,以便在Web环境中进行网页开发。
🈯从JavaScript中把ECMAScript踢出去,剩下的是什么?
剔出的话就非常受限了,JS将失去编程语言的特性,只剩下一些浏览器特定API,比如DOM、BOM等。这些API用于操作网页元素、与浏览器交互,但是无法构建完整的应用程序或者应用程序进行通用的编程任务。
🈯ES6新特性
蛮多的……看看能不能尽量往会的地方引,一下是之前整理过的↓

✅const一个数组 可以修改数组元素吗
const声明,表示变量的引用是不可改变的,也就是说不能重新分配一个不同的数组给变量。
换一句话说就是:数组是引用变量,能通过中括号和一些数组方法进行修改,但是完整替换是不行的。
map(map的实现方式) set weakmap weakset bigint
✅原型&原型链
原型
什么是原型呢?在JS中几乎每一个对象都有一个与之关联的对象,对象从这个关联的对象中继承一些属性,那么这个关联的对象就可以被称为是这个对象的原型。
值得注意的是,通过字面量创建的对象,原型对象都可以通过Object.prototype来引用。用new 构造函数创建的对象,原型是构造函数中prototype所指……
原型链
原型链是什么呢?原型链它是一种JS的主要继承方式。
它的基本思想就是通过原型,继承多个引用类型的属性和方法。它的基本构想就是在实例和原型间构造一条长链。
具体解释一下就是,每一个构造函数,都有一个属性指向原型对象,原型又有一个属性指回构造函数,通过这些构造函数实例化的对象有一个属性指向它的原型对象。这就是一个三要素连起来的小链了。然后我们可以想一下原型对象,这个原型对象可能继承了其他对象,那么它也有自己的原型对象,那么此时它也应该有一个属性来指向它的原型,以此类推,就出现了一条长长的原型链。
这使得,当我们要从一个对象中查询一个属性的时候,先会这个对象的自有属性中有无,如果有,很好找到了;如果没有,去看到它从它的原型中继承来的属性;如果有很好找到了;如果没有,去到它这个原型的原型中找,以此类推,直到JS规定的Object.prototype.__proto__ = null这个顶端终点为止。
✅数组底层数据结构
~从与其他语言对比上讲:
JS数组不像传统的语言一样是一块连续的区域,而是一种稀疏的,不必连续,允许有空隙的数据结构。且不像传统数组一样要求所有元素类型相同,元素可以是字符串甚至是对象、函数。
~从JS继承上讲:
JSArray实际上是继承自JSObject的,它是一个特殊对象。特殊在哪里呢?举个例子,数组[1, 2, 3],底层结构实际上是{ ‘0’: 1, ‘1’: 2, ‘2’: 3 , length: 3}——通过键值对的形式存储数组的索引和值,并且有一个带有length属性,且这个属性值为数组长度的对象,且会随着数组内元素的变化而相应变化。
~之前有看过一个大佬讲V8源码对于数组的实现-原文链接:
在用类似于我刚才举的例子的代码验证时,发现底层实际是个map,key索引value值。且JS数组有两种表现形式:一种是快数组FastElements,采用的快速后备存储结构FixedArray,一种是慢数组DictionaryElements,采用的是缓慢后备存储结构HashTable。
- FixedArray是V8实现的一个类似于数组的类,表示一段固定长度的连续的内存,适合一致、连续、密集的数组
- HashArray就是哈希表,根据散列表中的Key,通过散列函数,可以查询到内存存储的Value
快慢数组详细解释
- 快数组:快数组存储方式是线性的,新创建的空数组默认是快数组的存储方式。快数组长度可变,可根据数组的增删,通过扩容和收缩机制来动态调整存储空间大小。
- 扩容:
new_capacity = (old_capacity>>1) + old_capacity + 16——1.5倍旧空间+16。扩容后会将数组拷贝到新的空间里 - 收缩:
if(capicity > 2 * length + 16) {需要收缩 收缩的大小 = (length+1==old_length?(opacity-length)/2:capicity-length)} else {使用holes对象填充} - hoels空洞对象:分配了空间但是没有存放元素的位置。快数组有专门模式FastHoelyElements,也是分配连续空间,但给没有赋值的数组索引下会存储一个
undefined
- 扩容:
- 慢数组:慢数组存储方式是哈希表,不用开辟大块连续空间,但是维护起来效率比前者低一些。
- 快慢数组转换
- 快=>慢:这个 过程式动态进行的。
if(新容量 >= 3*扩容后的容量*2) {转换}if(new_index-cur_capicity >= 1024) {转换} - 慢=>快:这个过程是不可逆的,因为慢数组一旦变复杂(类型/稀疏),无法恢复成一个慢数组。
每次发现数组增长的时候,V8启发式算法检查其占用量,当空洞减少到一定程度(空间节省50%及以上)的时候,转换为快数组 - 各自优势:快数组,用空间换时间,空间大了效率高了;慢数组,用时间换空间,效率慢了空间小了。
- 快=>慢:这个 过程式动态进行的。
ArrayBuffer
ES6出的可以按需分配连续内存的数组。
1 | let bf = new ArrayBuffer(1024) // 申请到的连续空间 |
~总结一下就是:
JS数组和传统数组底层确实不一样,是通过JS V8引擎在底层做了一层封装,使用两种类型的数据结构实现了它,并能通过时间和空间纬度取舍从而优化它的性能。
🈯闭包
为什么闭包中的局部变量不会被垃圾回收清理?
讲一下js中的上下文
JS变量作用域
🈯对象/数组常用API
🈯new一个对象的过程
✅new一个对象和Object.create()的区别
new一个对象的具体做法是new Object(),此时使用的是Object构造函数,这样做,新建的对象原型将指向Object的prototype。
Object.create()的话,是继承括号内传进去的对象,也就是说这样创建的对象原型指向的是括号内的对象。
✅使用map构建的对象与普通的对象有什么不同
| 不同 | 普通对象 | map构建对象 |
|---|---|---|
| 键的类型 | String/Symbols | 任意类型 |
| 键值对的顺序 | 无序 | 插入顺序 |
| 大小获取 | 获取不到 | 通过.size获取到 |
| 迭代 | for/in Object.keys() | forEach for/of内置迭代 |
| 继承关系 | 继承它的原型或者Object的原型 | 继承Map的原型 |
✅深浅拷贝
浅拷贝
仅拷贝引用。
1 | Object.assign(target, source) |
深拷贝
引用也需要复制全新一份。
1 | for(){} |
💦深拷贝寿司
1 | function deepCopy(obj, visited = new WeakMap()) { |
✅平地起高楼
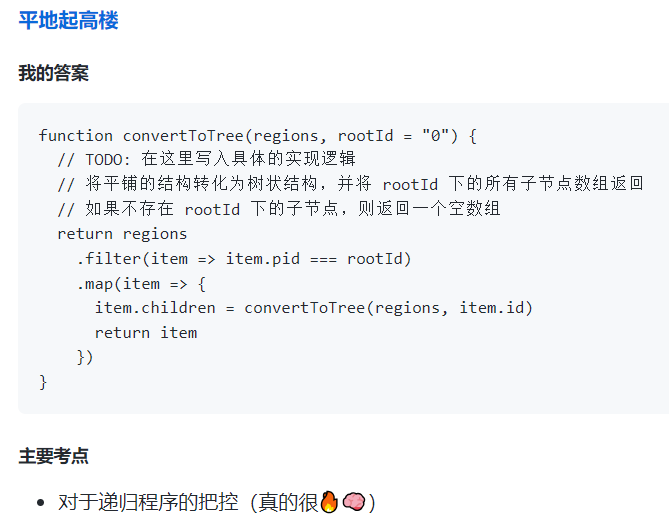
🈯判断一个变量是什么数据类型的
typeof 判断基本类型和引用类型,其中symbol->function null->object
instanceof详细判断引用类型
object.prototype.Stirng最为准确的判断方式
栈和队列和堆
- 栈是一种线性结构,先进后出。
- 队列是一种线性结构,先进先出。
- 堆是一种树状结构,用于存储动态分配的内存。没有特定顺序,满足堆属性。常用于大小根堆。
数组和链表
箭头函数
this 看代码说结果
特点
引入原因
✅apply/call/bind区别
同:
传参均为(所指向的对象,参数)
异(第二参):
- apply:数组
- call:
,分隔的序列 - bind:
,分隔的序列;返回的是一个可被调用的函数,方便在合适的时间调用。
✅🥬函数柯里化Currying
又称 Partial Evaluation部分求值
把传统的一次性接受多个参数的函数转化成——接受这个函数的函数,执行这个函数 所传入的参数数量 可以<=传统参数数量,可以返回一个继续接收剩余参数的函数。
这个和函数递归是联系起来的,当传统函数接受n多个参数的时候,currying函数可以是这样。
引用该网站所给示例,但是发现代码有误,自行修改了一下(已提交issue)。
1 | const currying = function (fn, ...args) { |
尾递归有什么用
js变量提升的好处
事件代理
事件委托
暂存死区是啥
event.target 和 event.currentTarget
Promise all race 手搓
1 | function all(promises) { |
实现一个函数柯里化加法函数,使得
1 | numberPlus(1, 2) |
1 | function curry(fn) { |
Promise如何解决异步问题(还有状态,还有如何控制并发,具体一些用法年数
promise和async
Await和Async的作用
🈯事件循环Event Loop(叙述、看代码说结果,一定要分清哪些哪些)
这里只放一些看代码说结果
为什么要把异步任务拆分成宏任务和微任务?
如何处理让多个异步任务让它们同时并发去执行?
✅DOM的回流(重排)和重绘
介绍
回流:元素位置/大小/内容发生变化的时候,触发重新布局,导致渲染树重新计算布局。
重绘:不会触发重新布局,仅改变一些颜色、透明度、背景色啥的。
如何最小化回流次数?
- 减少DOM深度,不必要不深排
- 减少CSS规则数量,移出未使用的CSS规则
- 动画等复杂渲染尽量脱离文档流
- 避免复杂的CSS选择器(尤其是子选择器)
TS
开源组织和工作都用到的语言,需要搞明白这个。打算做题+看项目。
在这里主要放面试题了。。
一些基本的
TS:是一种强类型的JS的超集,为JS提供了静态类型系统。
type: 在TS中用于定义类型别名、联合类型、交叉类型等复杂类型的声明方式。仅在编译阶段进行类型检查。
1 | type StringOrNumber = string | number // 联合 |
interface: 主要用于定义对象的类型和形状。支持继承和实现,适合创建复杂的对象类型。
1 | interface Animal { |
Type和Interface的区别?
首先两者都是仅在编译阶段才起作用。
🖽框架
Vue&React
✅实现原理上的区别
- 原始库 vs. 渐进框架:
- React是一个用于构建用户界面的JavaScript库,它关注于组件化和状态管理。React本身只提供了UI层面的解决方案,其他功能(如路由和状态管理)通常需要第三方库的支持。
- Vue.js是一个渐进框架,它提供了一整套的解决方案,包括视图层、路由、状态管理等。Vue的核心库相对更大,可以独立使用,但也可以与其他库和工具集成,根据需要逐渐引入功能。
- 语法和模板:
- React使用JSX(JavaScript XML)来定义组件的结构,这是一种在JavaScript中嵌入XML标记的语法。React组件可以通过JavaScript编写,JSX允许在代码中嵌入HTML样式的标记。.js .ts
- Vue.js使用模板语法,允许在HTML模板中直接声明组件的结构。Vue的模板语法类似于普通HTML,容易理解和使用。.vue(html)
- 数据绑定:
- React使用单向数据流,父组件通过props将数据传递给子组件,并通过回调函数进行状态管理。
- Vue.js使用双向数据绑定,可以通过
v-model指令轻松实现数据的双向绑定,这使得处理表单输入和交互更加简单。
就自身使用体验上,写Vue更像是写一些可以配置的页面,写React更像是用JSTS写一些可以基于逻辑来嵌套拼接的积木。
✅React单向数据流和Vue双向数据流的区别
Vue是有一种双向绑定数据的特性,具体指令是v-model=某数据。这个指令在元素中使用的时候,Vue的响应式系统会自动追踪数据的依赖关系,数据变化时会引发视图更新。我认为双向绑定的一个最显著的优点是表单数据可以随时更改。但是也不能算是缺点吧,如果过多使用v-model,每次改每次刷新,视图维护显得有点复杂。
React推崇的是单向数据流,具体就是父给子穿数据,子不能直接改父数据,而是需要绑定回调或者将状态提升给父来操作。这种固定的单相数据流的方式某种程度上简化数状态的管理,这也使得状态管理可预测,可控。
✅reactHOOK和vueHooks的区别
两者都是用于在函数式组件中管理状态和副作用的方式。
react的HOOK可以帮助在组件中使用不同的react功能。只允许在函数内进行使用。
1 | import { useState, useEffect } from 'react' |
vue的hooks为vue提供更灵活的方式来组织和共享组件逻辑。
1 | <template> |
✅vue2Mixin和vue3Hook的区别
Mixin是Vue2的一种选项式API特性,允许定义一组选项,可以拿来复用。主要用法:
1 | export const mixin = { |
1 | <script> |
Hook是Vue3的一种组合式API特性,可以在组件内以函数的形式定义,被拿去复用。主要用法:
1 | import { reactive, onMounted, onBeforeUnmount } from 'vue' |
1 | <script> |
✅虚拟DOM
虚拟DOM(Virtual DOM)是一种前端开发中的概念和技术,它是为了提高页面渲染性能而设计的。
在传统的前端开发中,当数据发生变化时,我们通常会直接操作真实的DOM来更新页面。这种做法可能会导致频繁的DOM操作,影响页面性能,特别是在数据变化频繁的复杂应用中。为了解决这个问题,虚拟DOM应运而生。
虚拟DOM是一个轻量级的、与真实DOM结构类似的JavaScript对象树。在虚拟DOM中,每个DOM元素都由一个JavaScript对象表示,这些对象可以包含元素的标签名、属性、文本内容以及子元素等信息。虚拟DOM可以通过比较新旧状态的差异来减少真实DOM的更新次数,从而提高页面渲染性能。
1 | // 虚拟DOM |
虚拟DOM的工作原理如下:
初始渲染:当应用首次加载时,将会创建一个虚拟DOM树,该树与真实DOM结构相对应。这个过程称为初始渲染。
数据变化:当应用数据发生变化时,会触发组件的重新渲染。此时,虚拟DOM会通过与之前的虚拟DOM树进行比较,找出新旧状态的差异,生成一个更新补丁(Patch)。
应用补丁:将生成的更新补丁应用到真实DOM上,实现页面的更新。
虚拟DOM的优势包括:
减少真实DOM操作:通过比较虚拟DOM树,减少了对真实DOM的直接操作次数,提高了页面渲染性能。
跨平台支持:虚拟DOM是对真实DOM的抽象,因此可以轻松实现在不同平台上的应用,例如浏览器、移动设备、服务器端等。
保持性能:在大规模数据更新时,虚拟DOM可以智能地批量处理DOM更新,减少了因频繁更新而导致的页面抖动。
虚拟DOM的一些常见实现包括React的虚拟DOM、Vue的虚拟DOM等。这些框架利用虚拟DOM机制,提供了高效的、响应式的组件化开发体验,使得前端开发更加高效和舒适。
✅React虚拟DOM和Vue虚拟DOM的区别
Vue
Vue的虚拟DOM是通过Vue组件的模板编译而来的:模板中包含数据绑定和指令,Vue将模板编译为渲染函数,该渲染函数生成虚拟DOM。
- 组件数据发生变化时,Vue会触发数据响应系统,检测哪些虚拟DOM节点需要更新
- 根据更新后的数据形成虚拟DOM树,此树与之前的虚拟DOM树进行比较
- 使用差异计算Diffing算法比较新旧虚拟DOM树,找出要更新的部分
- 将找到的差异转化为最小的DOM操作,应用于真实DOM上
React
React的虚拟DOM是React组件树的抽象表示,虚拟DOM由React元素构成,每个元素描述了一个组件的类型和属性。即:渲染组件时生成虚拟DOM。
- 组件渲染时,生成一个虚拟DOM树,树中包括组件元素的状态和属性
- 组件状态/属性发生变化时,React重新渲染组件,生成一个新的虚拟DOM树,与旧虚拟DOM树进行比较
- 使用协调Reconciliation算法,找出更新部分
- 将差异转化为最小DOM操作,应用于真实DOM上
Vue
✅Diffing算法
查阅发现是基于深搜。
基本思想如下:
- key是当前节点的唯一标识,可以告诉diff算法更改前后哪一对是同一节点
- 对于同一节点,才会进行精细化比较;否则就是直接拆出旧的,添加新的。
- 只进行同层比较,不会进行跨层比较。
在Javascript中,渲染
真实DOM的开销是非常大的,比如我们修改了某个数据,如果直接渲染到 真实DOM,会引起整个 DOM树 的回流和重绘。那么有没有可能实现只更新我们修改的那一小块DOM而不会引起整个DOM更新?此时我们就需要先根据真实DOM生成虚拟DOM,当虚拟DOM某个节点的数据改变后会生成一个新的Vnode,然后新的Vnode和旧的Vnodde进行比较,发现有不一样的地方就直接修改到真实DOM 上,然后使旧的Vnode的值变成新的Vnode。Vue就是使用虚拟DOM的创建和使用diff算法的比较从而进行上述操作。
diff算法的过程就是patch函数的调用,比较新旧节点,一边比较一边给 真实的DOM 打补丁。在采用
diff算法比较新旧节点的时候,只会进行同层级的比较。在patch方法中,首先比较新旧虚拟节点是否是同一个节点,如果不是同一个节点,那么就会将旧的节点删除掉,插入新的虚拟节点,然后再使用createElement函数创建 真实DOM,渲染到真实的 DOM树。如果是同一个节点,使用patchVnode函数比较新旧节点,包括属性更新、文本更新、子节点更新,新旧节点均有子节点,则需要进行diff算法,调用updateChildren方法,如果新节点没有文本内容而旧节点有文本内容,则需要将旧节点的文本删除,然后再增加子节点,如果新节点有文本内容,则直接替换旧节点的文本内容。
updateChildren方法将新旧节点的子节点都提取出来,然后使用的是双指针的方式进行四种优化策略循环比较。分别是:①、新前与旧前比较 ②、新后与旧后比较 ③、新后与旧前比较 ④、新前与旧后比较。如果四种优化策略方法均没有命中,则会进行遍历方法进行比较(源码中使用了Map对象进行了缓存,加快了比较的速率),如果设置了 key,就会使用key进行比较,找到当前的新节点的子节点在Map 中的映射位置,如果不存在,则需要添加节点,存在则需要移动节点。最后,循环结束之后,如果新节点还有剩余节点,则说明需要添加节点,如果旧节点还有剩余节点,则说明需要删除节点。
1 | // 创建虚拟DOM函数 |
渐进式框架
✅Vue2/Vue3区别
- 性能方面:Vue3通过新的响应式系统和编译器优化提高性能。Proxy Object.defineProperty
- 模板语法CompositionAPI: Vue3引入一套组合式API,方便更好组织和重用代码。Vue2混合mixin代码共享
- 更好的TS支持: 使用TS重构,自身提供更好的TS支持,类型声明,使得代码更可靠。
- 更轻量:包更小,可以更快加载运行。TreeShaking友好,按需打包
- 新特性:引入Teleport Suspense,在组件树中任何位置渲染内容,允许多个根节点;允许数组加载完成前显示占位符加载状态,无需遍历整个组件树。
- 语法API改进:更简洁直观,便于理解。生命周期钩子,Setup等
✅Vue2响应式原理
当将JS对象传给Vue实例作为一个data选项,Vue将遍历这个对象的所有property,使用Object.defineProperty把这些property全部转化为getter和setter。
Object.defineProperty
这是一个静态方法,会直接在一个对象里定义一个新属性或者修改其原有的属性,并返回对象。
2
Object.freeze(obj) // 阻止修改现有的obj的property
这些getter和setter是不可见的,但是内部可以让Vue可以追踪依赖,当这些property被访问修改时通知变更。
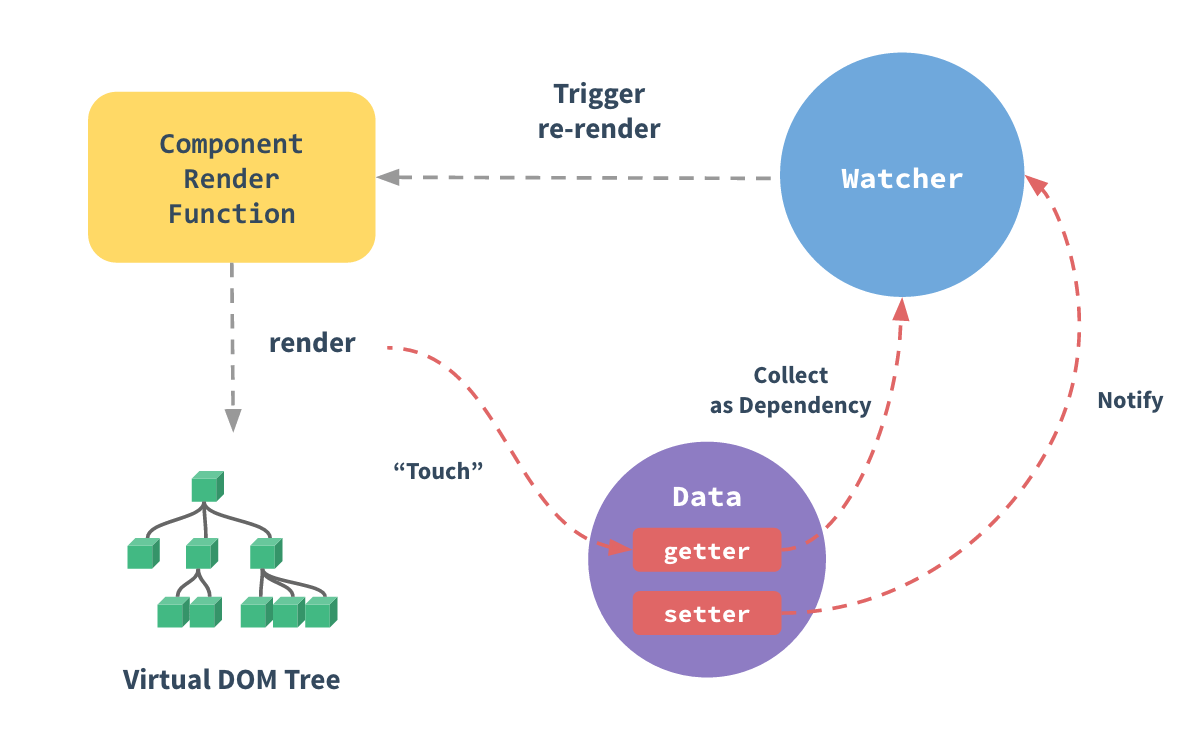
每一个组件实例都有一个watcher实例,这个实例会在组件渲染的过程中,把“接触”到的所有数据property记录为依赖。之后当依赖项的setter触发的时候,会通知watcher,从而使得这个依赖项关联的组件重新渲染。
对象和数组检测变化
对象
首先就是考虑到Vue在组件初始化的时候对对象进行遍历property和生成getter/setter,所以这些property需要在data选项中存在才能转换为响应式。
如果说这个实例已经创建好了,想额外添加一个property,但是Vue是不允许动态添加根级别响应式property,这个时候就可以使用Vue.set(vm.obj, name, val) / this.$set(...)方法来嵌套响应式property。
还有要使用Object.assign()/_.extend()de 的时候,要注意将原对象和混合进去的属性一起创建一个新对象。
数组
单独设置某索引下的值和修改数组的长度是不能被Vue检测到的。所以需要通过以下方式↓。
1 | this.$set(this.items, index, newVal) |
声明响应式
Vue不允许动态添加根级响应式,所以必须在初始化前声明所有的响应式,哪怕是一个空值。
为什么会这样?这样可以消除依赖项跟踪系统的一类边界情况,使得Vue能够更好配合类型检查工作。
异步更新队列
Vue在更新DOM时是异步执行的。当监听到数据发生变化的时候,会开启一个异步任务队列,缓冲同一事件循环中发生的所有数据变更。
也就是说很有可能同一个watcher被触发很多次,但其实为了避免不必要的计算和操作DOM,我们只想将这些很多次变化合成一次推入队列,所以需要在缓冲时去除重复数据。
然后在下一个事件循环’tick’中,Vue刷新队列执行实际要执行的工作,这部分工作显然是去重之后的。
1 | // Promise.then MutationObserver setImmediate setTimeout(fn, 0) |
✅Vue3响应式原理
Proxy
无需遍历对象,直接对整个对象生成一个Proxy实例。随后以来追踪→派发更新。
✅选项式API和组合式API
前者是基于后者实现的。Vue的基础知识和概念在两者之间是相通的。
前者以组件实例(this)为概念中心,将响应相关的细节抽象出来,强制按照选项来组织代码。见名知意,很适合上手。
后者核心思想是直接在函数作用域内定义响应式状态变量。并将多个函数中得到的状态组合起来处理复杂问题。形式自由,更适合逻辑自定义。
数据双向绑定原理
v-mode => v-bind and @input
数组添加了一个数字,vue怎么知道数组变化了
生命周期钩子
请求数据在哪个周期
组件通信
父子组件生命周期
✅计算属性和监听器的区别
computed watch
- 前者是函数返回值,返回对data属性的操作计算结果;后者是一个对象,键是需要观察的属性,值是回调
- 前者会被缓存;后者不会
- 前者大多用于一个属性受多个属性影响时使用;后者是监听一个属性对可能多条数据的影响
✅如何监听a.b.c,如何立即监听
1 | export defualt { |
✅ref
被用来给元素或子组件注册引用的信息(id的替代)。ref应用在html标签上获取的是真实DOM元素,应用在组件标签上获取的是组件实例对象。
1 | <div ref='haha'></div> |
ref refs
✅v-for为啥要加key
这跟虚拟DOM比较和视图更新有关。
假定这里有一个v-for列表,key可以作为列表中的每个项目的唯一标识,从而方便在比较这一个列表节点中所有子节点。
✅自定义指令
1 | Vue.directive('custom-directive', { |
1 | <template> |
自定义指令的定义包括一系列的选项,这些选项是指令的钩子函数。常见的自定义指令选项:
bind(el, binding, vnode):在指令第一次绑定到元素时触发。这里可以执行一些初始化操作。inserted(el, binding, vnode):当包含指令的元素插入到父元素中时触发。update(el, binding, vnode, oldVnode):当元素的绑定值发生变化时触发。componentUpdated(el, binding, vnode, oldVnode):当元素和它的子元素都被更新后触发。unbind(el, binding, vnode):在指令从元素上解绑时触发。
✅vue 动态添加响应式属性
1 | this.$set(this, 'name', 'val') |
✅在vue组件中 添加的定时器要手动清除吗
嗯嗯,为了防止内存泄漏和不必要的性能问题,是需要手动清除定时器的。
1 | beforeDestory() { |
✅mixin混入
mixin提供了一种灵活的方式,来分发组件中可复用的功能。一个混入对象可以包含任意组件选项。当一个组件使用某混入对象的时候,这个组件会吸纳这个混入对象的所有选项。
选项合并二三事
1 | let amixin = { |
全局混入
1 | // Please use it wisely~ |
硬核:自定义选项合并策略
上述先调用mixin和数据、键值以组件内数据为先等策略是选项合并的默认策略。
可以通过Vue.config.optionMergeStrategies进行自定义↓
1 | Vue.config.optionMergeStrategies.myOption = function(toVal, fromVal) { |
1 | // 举例 |
组件自定义事件
✅自定义插件
1 | // plugins/test.js创建 |
✅讲一下nextTick
在下一次DOM更新结束后执行指定的回调函数。
1 | Vue.component('example', { |
eventbus 和 vuex 分别适合什么场景
介绍vuex
mutations主要存放一些什么方法
✅vue-router的两种模式
对于一个url来说,什么是hash值?——#及其后面的内容就是hash值
hash值不包括在http请求中,即:hash值不会带给服务器
前者DOM后者BOM
- hash模式:
- 地址中永远带着#号,不美观
- 若以后将地址通过第三方手机app分享,若app校验严格,则地址会被标记为不合法
- 兼容性较好
- history模式:
- 地址干净,美观
- 兼容性和hash模式相比略差
- 应用部署上线时需要后端人员支持,解决刷新页面服务器404的问题
- 哈希模式(Hash Mode):
- URL 格式:在哈希模式下,URL 中的
#符号后面的部分被称为哈希片段(Hash Fragment)。例如,http://example.com/#/path中的/path是哈希片段。 - 原理:在哈希模式中,浏览器的 URL 中的哈希片段不会被发送到服务器。因此,当用户在单页面应用程序中进行导航时,Vue Router 实际上是通过 JavaScript 监听 URL 的哈希片段变化来管理路由状态的。
- 工作流程:
- 用户点击链接或手动输入 URL。
- 浏览器发送请求到服务器。
- 服务器返回单一的 HTML 文件,包括 Vue.js 应用程序的 JavaScript 代码。
- 浏览器加载页面并执行 JavaScript 代码,包括 Vue Router 配置。
- Vue Router 监听 URL 的哈希片段变化,根据哈希片段的不同渲染不同的视图。
- URL 格式:在哈希模式下,URL 中的
- 历史模式(History Mode):
- URL 格式:在历史模式下,URL 更加干净,不包含
#符号,例如http://example.com/path。 - 原理:历史模式使用 HTML5 历史记录 API,即
pushState和replaceState,来管理浏览器的历史记录和路由状态。这允许前端路由器更自然地处理 URL,并在不刷新页面的情况下更改路由。 - 工作流程:
- 用户点击链接或手动输入 URL。
- 浏览器发送请求到服务器。
- 服务器返回单一的 HTML 文件,包括 Vue.js 应用程序的 JavaScript 代码。
- 浏览器加载页面并执行 JavaScript 代码,包括 Vue Router 配置。
- Vue Router 使用历史记录 API 来修改浏览器的地址栏,而不触发页面的刷新,以匹配用户导航的路由。
- URL 格式:在历史模式下,URL 更加干净,不包含
✅vue-router页面跳转用的原生JS的哪一个API?
**
window.location.href**:通过修改window.location.href属性,你可以改变浏览器的当前 URL,从而实现页面跳转。例如,要将用户重定向到新的 URL,你可以使用以下代码:1
2javascriptCopy code
window.location.href = "https://example.com/new-page";**
window.location.replace()**:这个方法可以用来立即将用户重定向到一个新的 URL,并且不会在浏览器的历史记录中留下前一个页面的记录。例如:1
2javascriptCopy code
window.location.replace("https://example.com/new-page");**
window.location.assign()**:这个方法可以用于加载一个新的 URL,类似于window.location.href,但会在浏览器的历史记录中留下前一个页面的记录。例如:1
2javascriptCopy code
window.location.assign("https://example.com/new-page");**
window.location.reload()**:这个方法可以用于重新加载当前页面。如果你希望在用户执行某个操作后刷新页面,可以使用这个方法。
router原理
router 和 route
路由守卫如何配置?
路由守卫是可以帮助我们在路由导航发生前中后执行一些逻辑的自定义逻辑。
导航解析流程:
- 导航被触发
- 在失活的组件中调用beforeRouteLeave
- 调用全局beforeEach
- 在重用的组件中调用beforeRouteUpdate
- 在路由配置中调用beforeEnter
- 解析异步路由组件
- 在被激活的组件里调用beforeRouteEnter
- 调用全局的beforeResolve
- 导航被确认
- 调用全局的afterEach
- 触发DOM更新
- 调用beforeRouteEnter守卫中传给next的回调,创建好的组件实例会作为回调函数的参数传入
主要分为:
全局前置路由守卫
1 | router.beforeEach(async(to, from, next) => { |
全局解析守卫
解析守卫刚好会在被确认前、所有组件内守卫和异步路由组件被解析后调用。
1 | router.beforeResolve(async to => { |
全局后置钩子
1 | router.afterEach((to, from, failure) => { |
路由独享守卫
1 | export defualt [ |
组件内的守卫
提供了三个可配置的API:beforeRouteEnter beforeRouteUpdate beforeRouteLeave(Vue2)
onBeforeRouteUpdate onBeforeRouteLeave(Vue3)
1 | const UserDetails = { |
✅路由懒加载如何实现
在写routes规则的时候引入,而不是在开头引入。
这种方式可以减小初始加载包的大小,按需加载。
1 | export default [ |
vue路由跳转方式
axios实现原理(遇到非200怎么捕获err
封装axios
为什么有一种说法是vue适合中小型项目
React
Diff && Reconciliation(?)算法
传统Web应用往往会把实时更新的数据变化更新到页面上,也就是微小变动即要重新渲染DOM。
而React虚拟DOM是将定量内所有的操作累加起来,统计计算所有变化,然后统一更新一次DOM。
React分别对 tree diff component diff element diff 进行算法优化
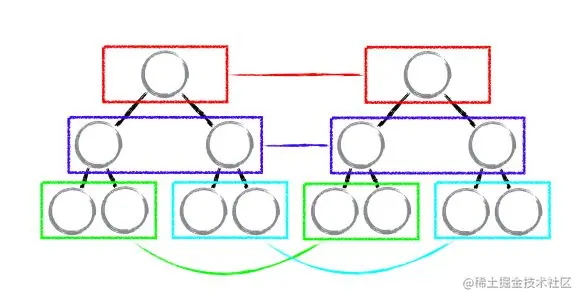
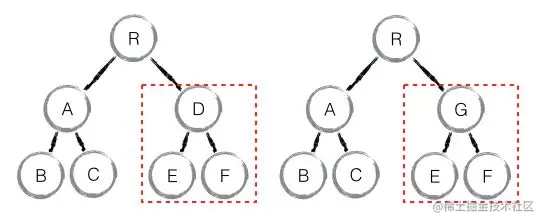
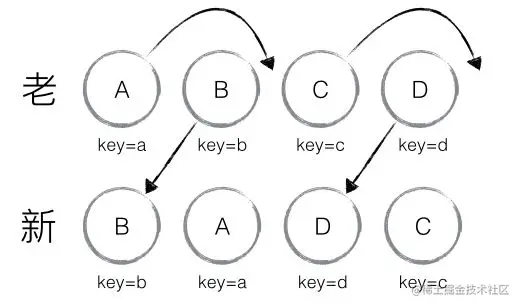
✅React设计哲学
在实现一个功能的时候,先将功能根据原型拆分成一套组件;
再使用React实现各个组件的静态,使用自上而下单项数据流方式进行数据的初步传递;
然后,找出UI交互所需的精简且完整的state,确保数据DRY(Don’t repeat yourself);
我们可以先分析组件中要用到/操作哪些数据,然后加以判定↓
- 不是从父组件拿到的
- 不是一直不变的
- 不是基于已存在与组件中的state或props拿到的
找出state合理的存放位置;
验证每一个基于特定state渲染的位置,找它们共同的父组件,考虑如何放置↓,用useState创建
- 一般情况下,选择共同的父组件
- 父组件的上层也可
- 找不到一个有意义拥有这个state的地方,单独创建一个组件管理这个state,并将该组件添加到它们父组件上层
添加反向数据流,实现动作响应;
React中的两种模型数据
props:传递的参数
state:组件的内存,追踪交互
两者可配合
Diff
react a.b.c 改变c的值会触发更新吗
生命周期钩子
组件通信
HOOK出现原因
HOOK应用场景
ReactHOOK为什么要在最外层使用?
HOOK优势和劣势
fiber架构出现的原因
react调度器怎么判断事件优先级
react-thunk的原理
useReducer的使用场景
useMemo底层原理
useCallback
路由懒加载
react为什么设计合成事件
SPA&MPA
通过动态重写当前页面来与用户交互,而非从服务器中重新加载整个页面。这种方法避免了页面之间切换打断用户体验,使应用程序更像是个桌面应用程序。
SPA
特点
- 单页面:用户在浏览该页面的时候不需要加载新的页面,而是通过JS动态加载能容并更新页面
- 无刷新导航:用户交互通常不会触发整个页面的刷新,而是获取数据后对当前页面的内容进行更新
- 前端路由:
优点
缺点
服务端渲染
服务端渲染SSR-Server Side Rendering
概念
是一种前端开发技术,通过在服务器进行页面初始渲染来提高性能。
核心思想:将网页的初始渲染工作从客户端转移到服务端。
与客户端的单页应用(SPA)相比,SSR优势在于:
- 更快的首屏加载:
- 服务端渲染的HTML无需等到所有JS下载执行完才显示
- 数据获取过程在首次访问时于服务端完成,比在客户端能有更快的数据库连接
- 统一的心智模型:相同的语言、声明式、面向组件的心智模型,无需前后来回转换
- 更好的SEO:爬虫可以直接看到完全渲染的页面
需要考虑的因素
- 在开发中,一些外部库需要特殊处理才能在SSR中运行;浏览器端一些代码只能在某些特定钩子中使用
- 构建配置和部署需要支持SSR
- 跟高的服务端负载,渲染一个完整的应用比仅托管静态资源更加占用CPU
SSR和SSG
MPA
静态站点生成SSG-Static Site Generation,被称为预渲染。将在构建之前就知道的数据和页面进行渲染成静态html然后放在服务器托管。
和SSR一样首屏加载速度都很快。而且比SSR花销更小,更容易部署——静态。
关于Next.js
支持SSR也支持SSG
静态生成
- 营销页面
- 产品列表
- 博客简历
- 帮助文档
当仅使用静态生成,遇到需要现实请求后数据的时候,可以将静态生成和客户端渲染结合,或者使用服务器渲染。
服务端端渲染
在每次页面请求时重新生成页面的HTML。
这东西放在项目里阐述吧,内容很多。。。
mvc->mvvm的过渡,对比mvc与mvvm
require和import的区别
🛠️前端工程化
pnpm解决了npm什么痛点
Webpack和Vite打包的区别
Webpack
webpack tree shaking的原理
webpack常用配置?
loader是怎么样的机制?
webpack的出现解决了什么问题?
Vite
为什么Vite更快
🔮Git
基础
基本使用:
git commit
git checkout -b 分支名,创建分支
git merge 分支,生成一次新的合并commit在分支上
git rebase 分支,将分支合并到指定分支
相对引用:
git checkout 提交记录,使得HEAD分离出来
git checkout 分支^,跳到分支的parent提交点
git checkout HEAD^,跳到HEAD节点的parent提交点
git checkout HEAD~3,向上跳了三次
git branch -f 分支 HEAD~3,强制修改分支位置到第三级parent提交
撤销变更
git reset HEAD~1,改写历史,向上移动分支,撤销一次变更
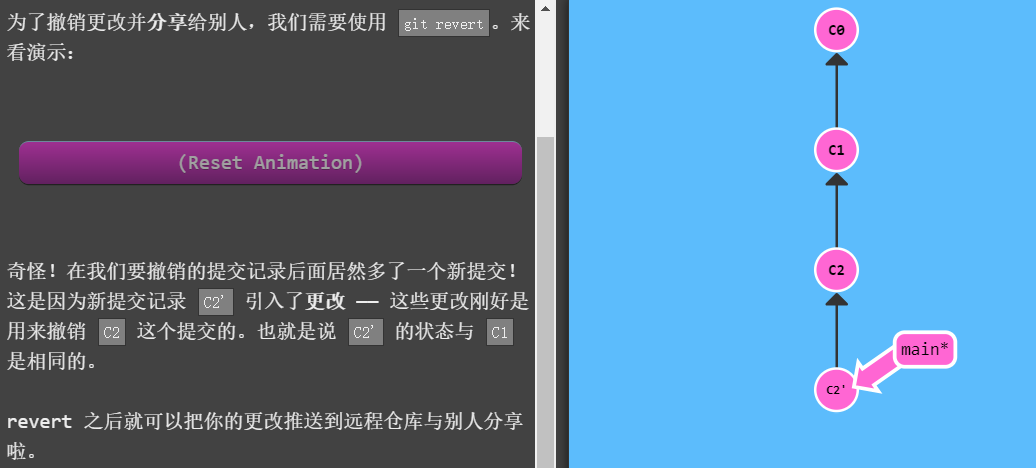
git revert HEAD,撤销一次更改并分享给别人
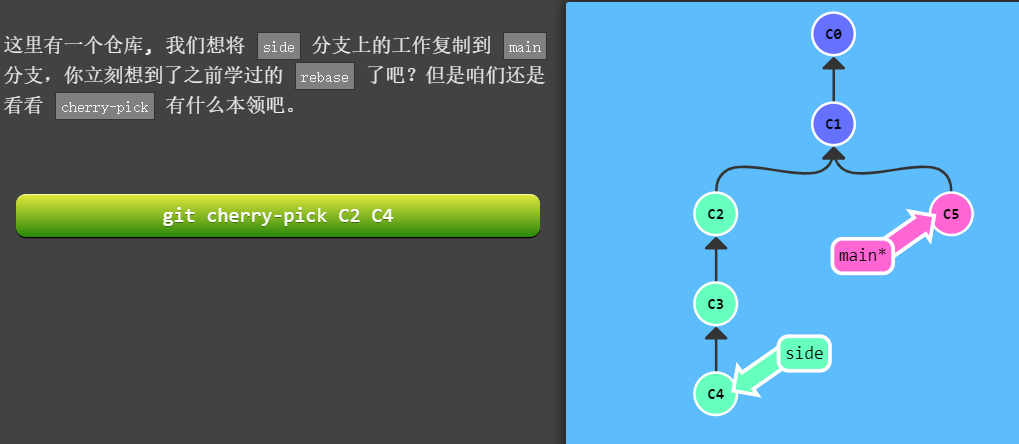
整理提交记录
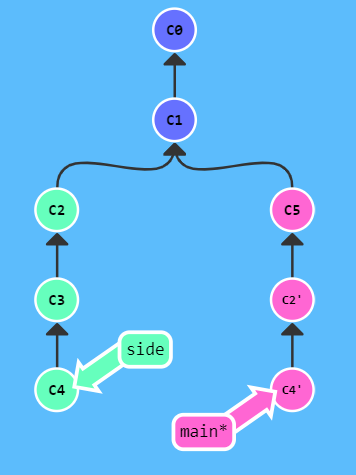
- git cherry-pick
 →
→ 
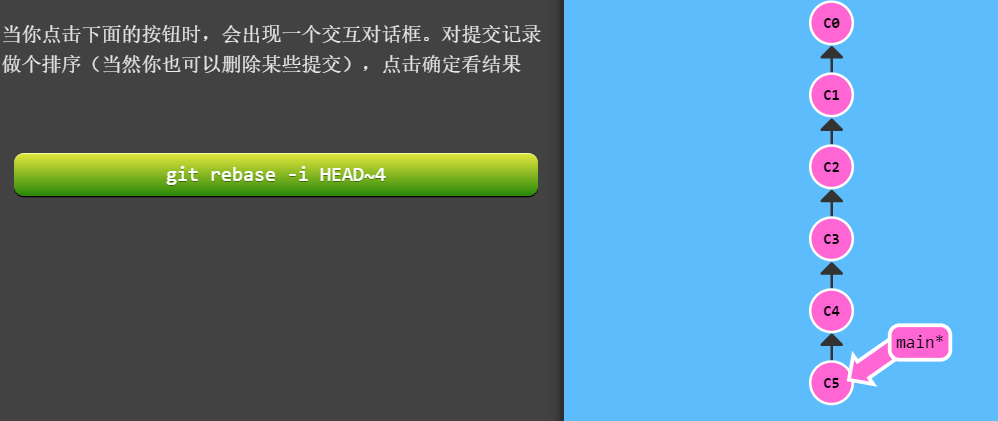
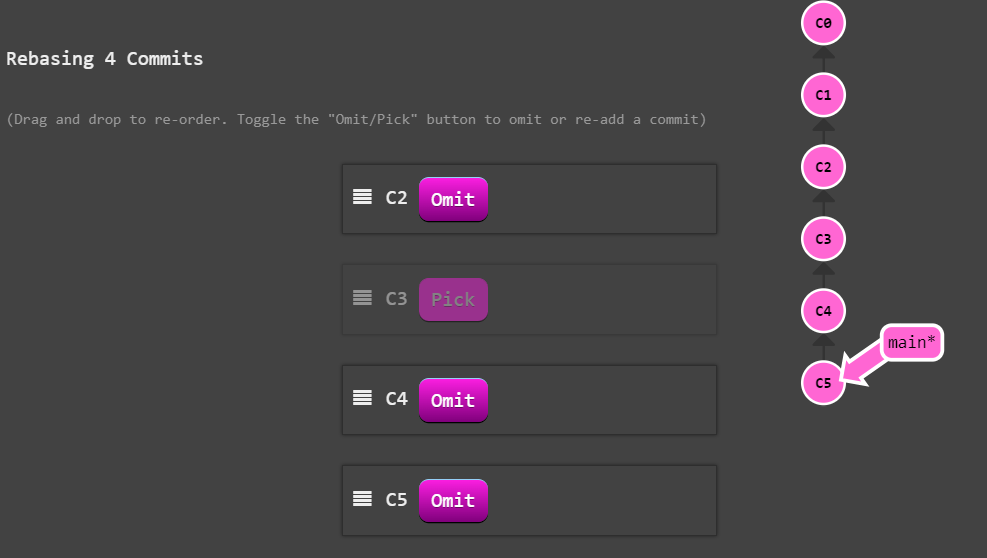
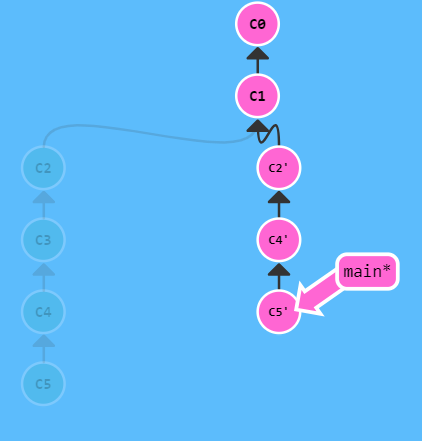
- 交互式rebase git rebase –interactive(-i)
git merge main 和 git rebase main的区别
merge
merge会在feature分支中新增一个新的merge commit,然后将两个分支的历史联系在一起。
是一种非破坏性的操作,对现有的分支不会造成任何方式的改变。
分支每次需要合并上游更改时,它都产生一个额外的和并提交。
如果main分支提交十分活跃,那么可能会严重污染feature分支记录,可以使用git log来解决。
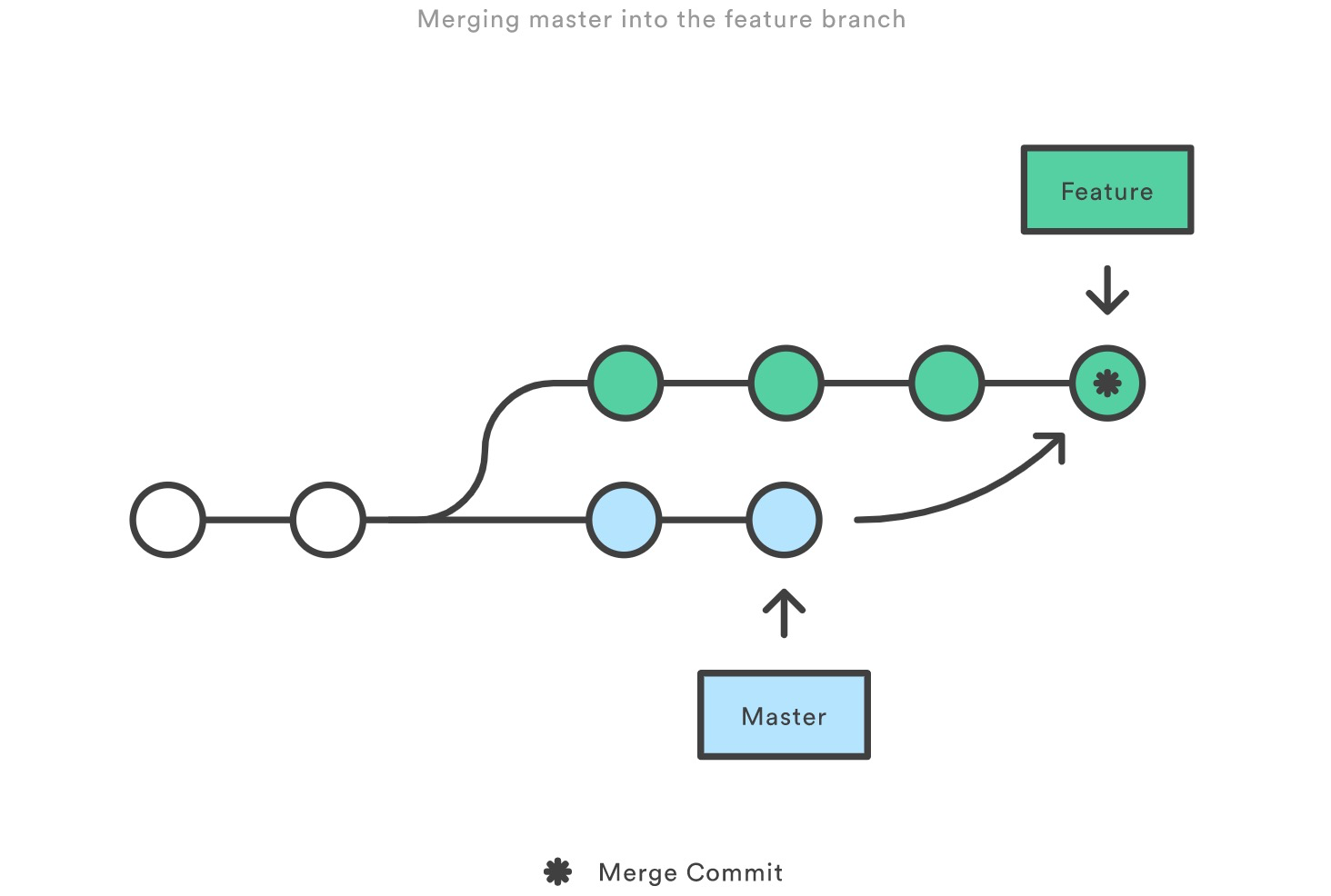
rebase
rebase会将整个feature分支移动到main分支的顶端,有效整合了所有main分支的提交。
rebase通过为原始分支中每个提交创建全新commits来重写项目历史记录。
rebase能使得获得更清晰的项目历史,消除了git merge那样不必要的和并提交。
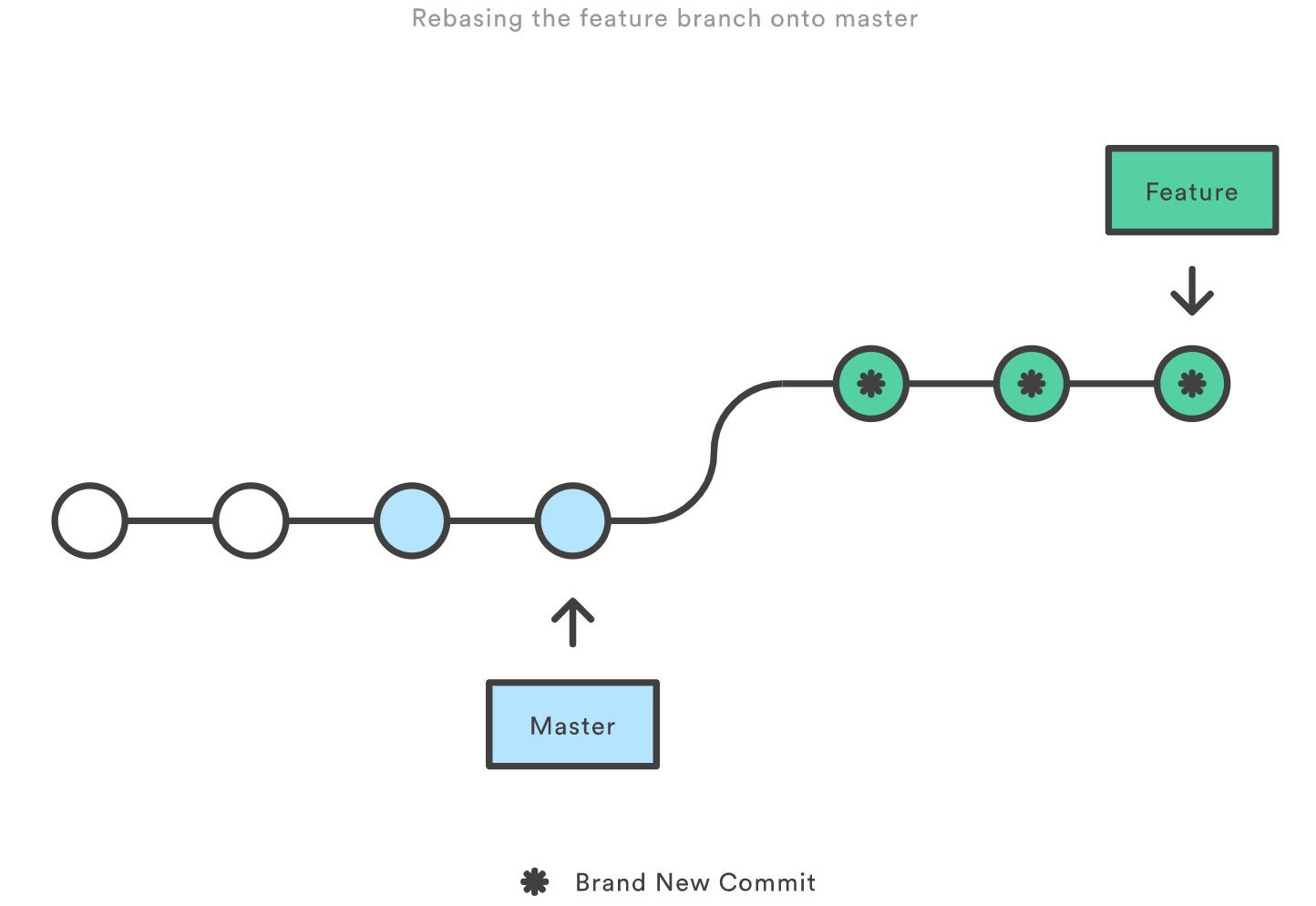
rebase rebase feature,等效与创建了新提交,且老的提交只是不能再被访问使用
🧰项目
工作经历
客户端直传

好处:少在网络中传输一次,节约开销。
实现:
- 跨域
- 安全授权
- 服务端STS临时访问凭证:适用于基于分片上传大文件、基于分片断点续传场景,需要进行缓存和刷新优化,不要频繁调用。
- 服务端生成Post签名和PostPolicy:适合限制客户端上传文件大小类型等,不支持分片上传大文件、基于分片断点续传场景。
- 服务端生成签名URL:简单上传,不适合大文件、基于分片断点续传场景。
TS相关
electron
技术难点
路由二次封装
状态管理
状态管理
前端工程化
使用Prisma简化数据库操作
1 | npm install prisma --save--dev |
1 | // .env.development.local |
1 | // lib/db.js |
1 | // prisma/schema.prisma |
1 | // CRUD |
NextAuth.js简化用户登录认证
1 | npm install next-auth |
1 | // lib/auth.js |
1 | // auth/[...nextauth]/route.js |
token怎么生成的?token怎么加密?
useMemo和memo
一个在每次重新渲染后缓存计算结果的钩子。
- 跳过代价昂贵的重新计算
- 跳过组件的重新渲染
- 记忆另一个HOOK依赖
- 记忆一个函数
1 | export default function TodoList({ todos, theme, tab }) { |
useMemo 和 useCallback
1 | // 包裹函数显得有些笨拙 |
useContext
一个可以让读取和订阅组件中的context钩子。
- 向数组深层传递数据
- 通过context更新传递数据
- 指定回退默认值
- 覆盖组件树一部分的context
- 在传递对象的和函数时优化重新渲染
如何进行状态管理?
1 | // contexts/TodoContext.js |
useReducer
一个允许向组件中添加一个reducer。和useState有相似的效果,在组件顶层创建用于状态管理。
- 一般用法就是创建一个
reducer(state, action)方法,定义操作状态 - 然后
const [state, dispatch] = useReducer(reducer, initialArg, init?),给state一个初始为init的状态,使用dispatch函数和reducer函数统一操作管理状态
1 | function reducer(state, action) { |
性能优化
业务思考
什么是状态?为什么要管理状态?组件是如何感知到状态的变化的?state和props的区别?
状态是React中一个非常重要的概念之一。表示一个组件的数据,这些数据可以随着时间推移而改变,通常用于存储组件可变的信息。
为何管理状态
- 响应用户状态:捕获变化处理变化(按钮、键入文本
- 数据驱动视图:这是React的一个核心思想,用数据状态变化驱动视图变化代替了自主操作DOM
- 组件通信:将状态和自定义事件回调传递给子组件,方便父子组件之间通信
- 性能优化:有效管理状态更新,必要时重新渲染组件
组件如何感知状态变化
- setState(过时了已经…)
- useState
- useEffect
state和props的区别
- State(状态): 是组件自己管理和维护的数据,用于存储组件的可变信息。可以通过
this.state(在类组件中)或useState(在函数式组件中)来声明和更新状态。状态通常在组件内部使用,只能被组件自身修改。 - Props(属性): 是从父组件传递给子组件的数据。它们是不可变的,子组件不能直接修改props。props用于在组件之间传递数据,以使组件可以展示不同的信息或根据外部数据进行自定义渲染。
实现无限列表的加载
为什么二次封装axios
为什么二次封装vuerouter
如何避免一次性出现许多错误弹出框
实现轮播图
点击发请求按键优化
快速点击几个item,每一个item携带自己的id发送请求,dom展示数据,最后显示的是哪个item的数据?怎么让页面显示的是最后一个点击的item的数据?
如何提高性能
如何保证代码上线稳定性
关于登录
token 存在 localStorage 里有风险吗?
有风险,cv
token 是放在 cookie 里更合理还是放到 localStorage 里更合理?
token 存到 localStorage,是没有过期时间的,怎么实现有过期时间呢?
🥴手撕
CSS相关
实现三角形
1 | #triangle { |
(为什么会被问到这样的问题??)[]
轮播图
图片背景
图片自适应
图片在盒子里不会被剪裁,宽或高需要撑满盒子,不会被拉伸挤压。
1 | .container { |
图片在盒子里宽或高需要撑满盒子,不留空隙,可以适当剪裁。
1 | .image { |
左侧固定,右侧占满
1 | .container { |
业务相关
✅html写一个计时器,页面上展示读秒,三个按钮,分别是开始,停止和重置
1 | <div id="timer">0</div> |
1 | let timer = null |
✅有一个表单,表单内有个提交按钮,写一个避免重复提交的通用方案
1 | <form id="myForm"> |
1 | const form = document.getElementById('myForm') |
{ id:xxx , parentId: yyy, order: 1 } 这种结构的数组转化成一个树型结构,order代表同组子节点的优先级,怎么优化,减少循环次数
💥父子组件通信
忘得差不多了,似乎是这样字写
React
1 | function grandfather() { |
Vue
1 | <body> |
语法特性相关
✅0.1 + 0.2 != 0.3原因,解决
JS浮点数精度问题。JavaScript使用IEEE 754标准来表示数字,该标准采用二进制浮点数表示法,而不是使用十进制浮点数表示法。在二进制浮点数表示法中,有些小数无法准确表示,因此可能会导致计算结果不精确。
0.1 和 0.2 在二进制浮点数表示法中无法精确表示,它们会被近似为有限的二进制小数,导致计算时产生微小舍入误差。
1 | 0.1 (十进制) ≈ 0.00011001100110011001100110011001100110011001100110011... (二进制) |
解决1:先将小数转换为整数,计算后还原成小数。
解决2:用专门的精确计算库(bignumber.js math.js)。
1 | let ans1 = new BigNumber(0.1 + 0.2) |
✅二进制转换十进制为什么会造成精度丢失?
因为二进制无法准确表示小数。IEEE 754二进制浮点表示法中,一个浮点数由符号位、指数位、尾数位表示,指数位指明小数点的位置,尾数位是小数点后的二进制表示。
而一些小数比如0.1,在二进制表示中可能是一个循环小数的表示,也就是说无法精确表示0.1↑,所以当这样的无限循环小数从二进制转换回十进制后,就会出现精度丢失。
✅指定深度的flat
主要是个递归
- 如果深度不合法,报错
- 如果深度=1,直接返回
- 如果深度>1,遍历
- 如果遍历到的元素是数组,递归,且传入深度 = 深度 - 1,然后添加到结果集
- 如果遍历到的元素是基本,直接添加到结果集
1 | function flat(arr, depth = 1) { |
✅This的指向
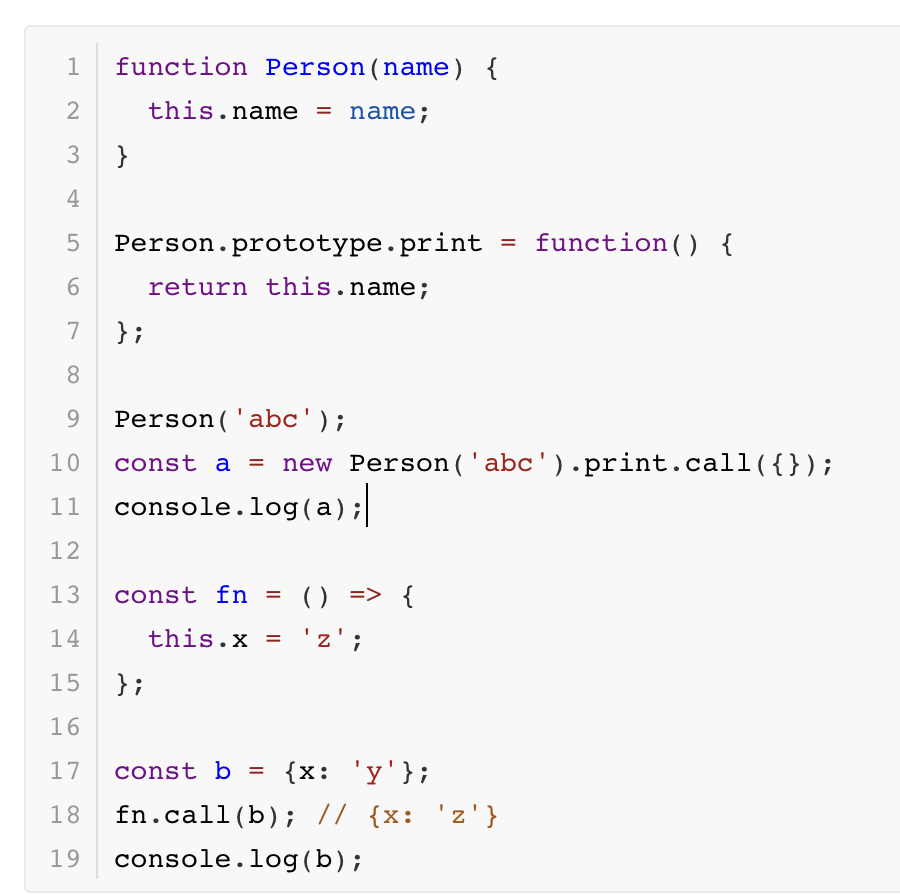
1 | // => undefined 构造函数的this指向了空对象,因此this.name是undefined |
✅ES6 var一个对象
看输出结果
1 | // T1 |
Promise.all
任何一个Promise被拒绝,返回的Promise将被拒绝,并携带拒绝原因。
1 | const promise1 = Promise.resolve(3); |
💥异步任务队列,可以同时指定任务队列长度
1 | class AsyncQueue { |
💥超时重传Promise.race
1 | // 创建一个函数来执行网络请求 |
✅节流函数的多种实现方式
时间戳
1 | function throttled(fn, delay = 500) { |
延时器
1 | function throttled(fn, delay = 500) { |
延时器+时间戳——更加精确的节流
1 | function throttled(fn, delay = 500) { |
✅防抖函数的实现
1 | function debounced(fn, wait = 500) { |
1 | // 立即执行 |
1 | // 传入第三参数控制是否立即执行 |
1 | // 拓展取消功能 |
深拷贝的实现
算法相关
17. 电话号码的字母组合
深/广搜
1 | /** |
排序有哪些算法?sort()函数排序用的是哪种排序算法?
sort是快排
如何对单链表进行排序
如何判断一个json数组是另外一个json数组的子集
1 | function isSubset(subset, superset) { |
用栈判断括号匹配的具体过程
数组去重
写一个函数进行数字格式转换
1 | // 数字转为含分隔符,并保留两位小数的字符串(写在第一面背面) |
解法如下:
对象数组去重
找出最长不重复字母的子串
最长递增子序列
如何将浮点数点左边的数每三位添加一个逗号,如12000000.11转化为12,000,000.11?
1 | function commafy(num){ |
✅console.log(transform(‘123abc456def’)); //abc123def456”
1 | function transform(str) { |
分隔字符串
1 | input: str: "1234567,123456,1234567,1234567890,123456789,1,2,3,4,5,6" |
解法如下:
让console.error(a == 1 && a == 2 && a == 3)打印结果为true。
解法如下:
1 | let a = { |
给定一个无重复元素的整数数组nums,找出其中没有出现的最小正整数
1 | 空间复杂度O(1),时间复杂度O(n) |
随机打乱数组
发红包
大根堆
给定一个不重复元素的整数数组,来构建最大根二叉树, 二叉树的根节点是数组中的最大值,使用数组最大值左侧的部分构建二叉树的左子树,右侧部分构建二叉树的右子树, 左右子树都是最大根二叉树。
例子:input:[1,3,2,6,4,5]
ouput:
6
3 5
1 2 4
💢LazyMan
实现一个LazyMan,可以按照以下方式调用
1 | LazyMan("Hank") |
解题:
1 | function LazyMan(name) { |
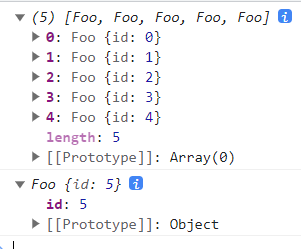
💥实现一个计数构造函数
写一个构造函数 Foo,该函数每个实例为一个对象,形如 {id: N},其中 N 表示第 N 次调用得到的。
要求:
1、不能使用全局变量
2、直接调用 Foo() 也会返回实例化的对象
3、实例化的对象必须是 Foo 的实例
解题:
1 | function Foo() { |
开平方根(整数、小数)
数字阶乘
💥各种排序
冒泡排序$O(n^2)$
1 | function bubbleSort(arr) { |
插入排序$O(n^2)$
1 | function insertSort(arr) { |
选择排序$O(n^2)$
1 | function selectSort(arr) { |
快速排序$O(nlog2(n))$
1 | function quickSort(arr) { |
希尔排序$O(n^{1.3})$第一个突破$O(n^2)$的排序算法
1 | function shellSort(arr) { |
归并排序$O(nlog2(n))$
1 | function mergeSort(arr) { |
二分查找法$O(log2(n))$
1 | // 非递归 |
括号匹配
最长重复子数组
二叉树最大深度
大数相乘
hardMan()
打家劫舍2
打家劫舍3
最长字符串链(leecode的1048题)
子类继承父类
对列表元素中某一属性进行排序
实现一个函数,函数有两个参数,第一个参数为一个字符串,第二个参数为一个数字
1 | 例如:输入 abcdefghij 3 |
我是这么想的:
1 | function test(str, num) { |
实现 lodash.get
LC岛屿数量,最大岛屿面积
2208. 将数组和减半的最少操作次数,建个堆吧
🧮设计模式
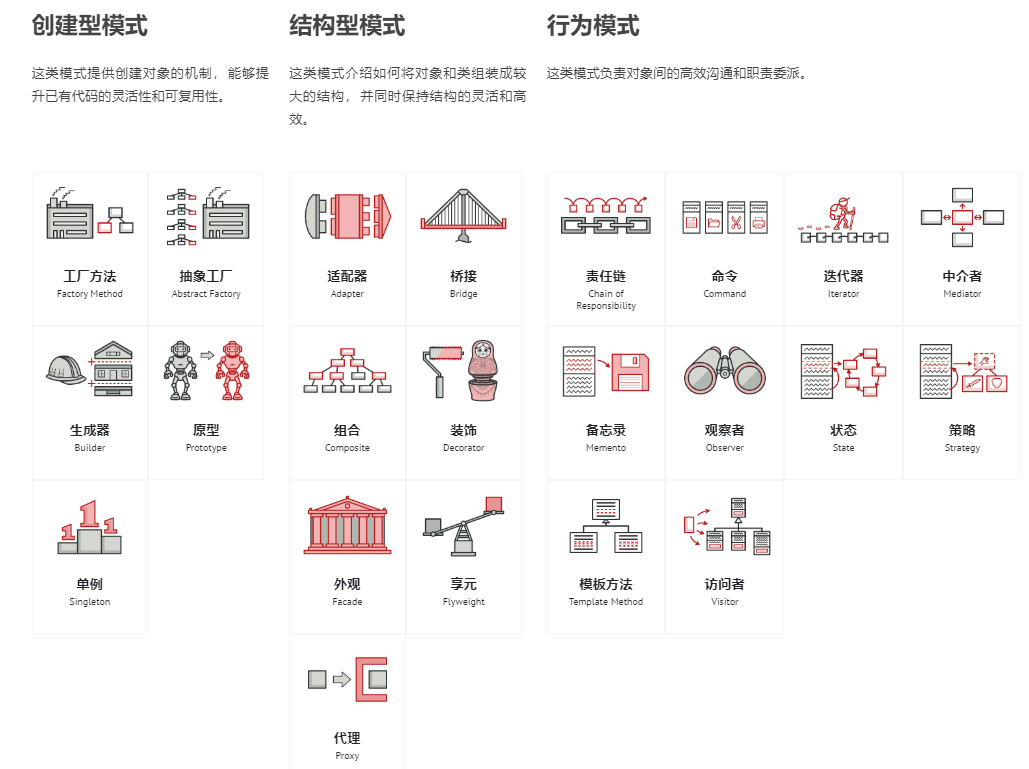
定义:设计模式是针对特定问题的简洁优雅的解决方案。
设计模式分为三大类:创建、结构、行为规范。
创建
单例模式
意图:
- 确保一个类只有一个实例遵。循真理单点性的观点,遵循单一职责原则(FCC:不可复制不可更改)
- 并提供该实例的全局访问点。方便调用访问。
单例模式禁止通过除特殊构建方法以外的任何方式来创建自身类的对象。该方法可以创建一个新对象,如若该对象已经被创建,那么返回的应是已有的对象。
1 | class Singleton { |
结构:↑
案例:以下是对一个单一对象进行设置,从而禁止修改/添加对象中任何内容。
1 | // 对象字面量 |
工厂方法
提供创建对象的接口,对象被创建后可以被修改。将创建对象的逻辑集中在一个地方,简化代码,使更易组织。
1 | // 工厂函数 |
抽象工厂
允许在不指定具体类的情况下生成一系列相关的对象。创建仅共享某些属性方法的对象。
给客户端提供一个可以交互的抽象工厂,抽象工厂可以通过特定逻辑调用具体工厂,具体工厂返回最终对象。
1 | // 具体工厂 |
构造器模式
构造器模式分步骤创建对象。通过不同的函数和方法对对象添加属性和方法。通过不同的实体分开创建属性和方法。
通过类或构造函数创建的实例通常继承了所有的属性和方法。但是如果使用构造器,我们可以只应用我们需要的步骤来创建对象,更加灵活。
1 | const bug1 = { |
原型
允许将一个对象作为蓝图来创建另一个新对象。新对象继承原对象的属性和方法。
1 | const obj1 = { |
结构
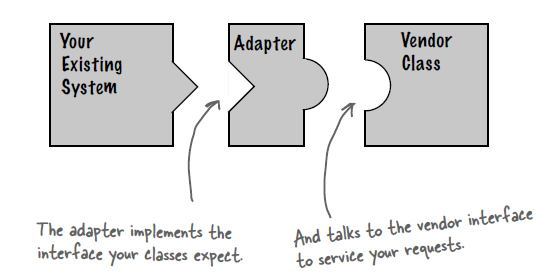
适配器
允许两个接口不兼容的对象相互交互。
1 | // 旧的温度计类 |
装饰
通过一个对象包裹原来的对象,从而给原来的对象增添新的行为。
可以回想一下React项目中状态管理的配置。
1 | export defualt function ContextProvider = ({ children }) => { |
外观
给库、框架以及其他复杂的类集提供简化的接口。
想一下很多封装的接口方法,很多组件库封装好的组件。
代理
为另一个对象提供替代或占位符。控制对原始对象的访问,当请求到达原始对象之前/后执行某种操作。
想一下中间件,我们可以在请求到达前/中/后执行一段代码。
享元模式
它摒弃了在每个对象中保存所有数据的方式, 通过共享多个对象所共有的相同状态, 让你能在有限的内存容量中载入更多对象。
行为范式
责任链
责任链将请求通过处理链传递。(不同的实体协作实行任务)
迭代器
用于遍历集合元素。有很多迭代方法的呃呃。
观察者模式
允许定义一个订阅机制,通知多个对象,他们正在观察的这一个对象发生的变化事件。
观察者模式通常是同步的。
发布-订阅模式
允许定义一个事件中心(消息代理),允许发布者和订阅者之间解耦。
发布订阅模式通常是异步的,发布者发布事件之后不会立即通知订阅者,而是等待订阅者订阅相关事件的时候才会通知。
😎自我介绍
首先警告一下你自己,不要出现‘就是就是就是’‘怎么说怎么说’这种口头禅,老可恶了录音里听着!
然后就是,带耳机!真的很容易听不清面试官的问题。
静思,感觉说不完整的的不如直接说不知道该怎么叙述。
面试开头的自我介绍
为什么选择前端
所敲即所见,所见即所得
怎么学习的前端
为什么选择这个城市
👔反问
纯觉得自己菜:
公司开发部门人员结构,同岗位人员数量,团队氛围,日常技术交流
对业务感兴趣:
官网看到…具体是什么样的(询问一些猜想)
比较有过的把握:
培养实习生的路线是怎样的呢?
分配任务是怎样的呢?
需要提前准备一些什么?
 (wechat)可以请我喝瓶水嘛?
(wechat)可以请我喝瓶水嘛? (alipay)可以请我吃淀粉肠嘛?
(alipay)可以请我吃淀粉肠嘛? (QQ)可以为我充Q币嘛?
(QQ)可以为我充Q币嘛?